
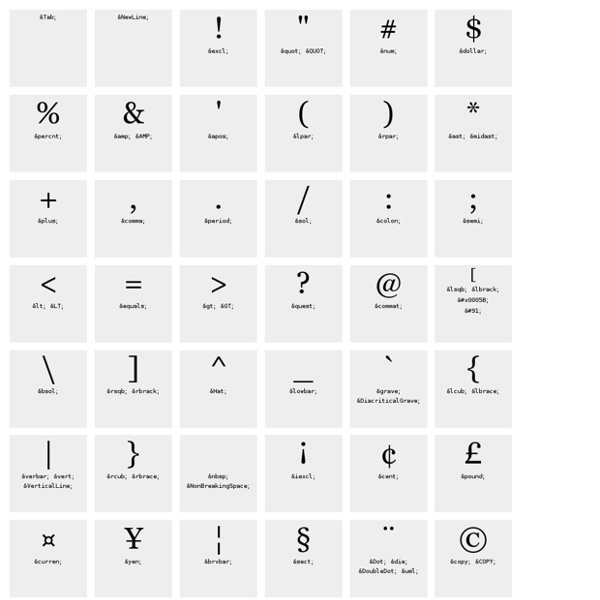
https://dev.w3.org/html5/html-author/charref
Related: Codage, encodage de caractères : UNICODE, ASCII, UTF-8 etc...UTF-8 L’UTF-8 est utilisé par 82,2 % des sites web en décembre 2014[2], 87,6 % en 2016[3], 90,5 % en 2017[4] et près de 93,1% en février 2019[5]. Par sa nature, UTF-8 est d’un usage de plus en plus courant sur Internet, et dans les systèmes devant échanger de l'information. Il s’agit également du codage le plus utilisé dans les systèmes GNU, Linux et compatibles pour gérer le plus simplement possible des textes et leurs traductions dans tous les systèmes d’écritures et tous les alphabets du monde. Liens avec la norme internationale ISO/CEI 10646 et les standards Unicode et d’Internet[modifier | modifier le code] UTF-8 est officiellement défini dans la norme ISO/CEI 10646 depuis son adoption dans un amendement publié en 1996. Il fut aussi décrit dans le standard Unicode et fait partie de ce standard depuis la version 3.0 publiée en 2000.
L'érotisme discret des claviers mécaniques customisés Les claviers, c’était mieux avant. Rappelez-vous de votre enfance, quand vous frappiez les touches profondes et bruyantes de l’ordinateur familial pour insulter Adibou. Ces machines tiraient toute leur personnalité (et leurs décibels) d’un système d’interrupteur mécanique : en enfonçant l’une de leurs touches, on activait un assemblage de pièces de métal et de ressorts qui finissait par établir un contact électrique. Au fil du temps, ce dispositif a été remplacé par des dômes de caoutchouc, plus économiques mais moins confortables d’utilisation. Un scandale !
ISO/CEI 8859-1 La norme ISO 8859-1, dont le nom complet est ISO/CEI 8859-1, et qui est souvent appelée Latin-1 ou Europe occidentale, forme la première partie de la norme internationale ISO/CEI 8859, qui est une norme de l’Organisation internationale de normalisation pour le codage des caractères en informatique. Dans les pays occidentaux, cette norme était utilisée par de nombreux systèmes d’exploitation, dont UNIX, Windows ou AmigaOS. Elle a donné lieu à quelques extensions et adaptations, dont Windows-1252 et ISO 8859-15. ™ Notation Preface en ligne Le système a été arrêté après 60 minutes d'inactivité (1). L'essentiel de vos travaux est cependant sauvegardé. Vous allez être redirigé vers la page d'accueil. Il vous faudra vous identifier de nouveau (bouton Connexion) pour pouvoir reprendre votre dossier en cours. Si vous rencontrez la moindre difficulté,n'hésitez pas à contacterNOTA-PME au 33 (0)1 42 67 52 56. Il semble que la connexion Internet est d'une très grande lenteur ou a été momentanément interrompue, ce qui aurait provoqué une anomalie (6).
ISO/CEI 8859-15 Différences avec ISO 8859-1[modifier | modifier le code] Le jeu de caractères ISO/CEI 8859-15 peut être considéré comme une mise à jour de la norme ISO 8859-1, avec laquelle il est identique à l'exception de huit caractères[1]. Note : les codes numériques sont donnés en base hexadécimale.
SKUZE GENERATOR WEB : mail : gaf@free.fr (pompé sur le pipotron (eh oui, nous sommes de grosses feignasses mais vous le savez déjà)) Pas envie d'aller au boulot ce matin ? Il fait pas beau ? Il fait trop froid ? On est bien sous sa grosse couette ? Windows-1252 Un article de Wikipédia, l'encyclopédie libre. Windows-1252 ou CP1252 est un jeu de caractères, utilisé historiquement par défaut sur le système d'exploitation Microsoft Windows en anglais et dans les principales langues d’Europe de l’Ouest, dont le français. Contexte[modifier | modifier le code] Au début des années 1990, l'utilisation du codage Windows-1252 se développe en Occident, avec la diffusion de Windows 3.x. Les caractères codés sont appelés par confusion « ANSI » au lieu d'« occidentaux » ((en)« Western »)[1].
Unicode Un article de Wikipédia, l'encyclopédie libre. Unicode est un standard informatique qui permet des échanges de textes dans différentes langues, à un niveau mondial. Il est développé par le Consortium Unicode, qui vise à permettre le codage de texte écrit en donnant à tout caractère de n'importe quel système d'écriture un nom et un identifiant numérique, et ce de manière unifiée, quelle que soit la plate-forme informatique ou le logiciel. Ce standard est lié à la norme ISO/CEI 10646 qui en est un sur-ensemble[1]. La dernière version, Unicode 8.0, est publiée depuis le 17 juin 2015[2]. But[modifier | modifier le code]
American Standard Code for Information Interchange Un article de Wikipédia, l'encyclopédie libre. Les 95 caractères ASCII affichables : !"#$%&'()*+,-./ 0123456789:;<=>? @ABCDEFGHIJKLMNO PQRSTUVWXYZ[\]^_ `abcdefghijklmno pqrstuvwxyz{|}~ Cette section doit être recyclée.