
BIG Data Analytics Pipeline. "Big Data Analytics" has recently been one of the hottest buzzwords.

It is a combination of "Big Data" and "Deep Analysis". The former is a phenomenon of Web2.0 where a lot of transaction and user activity data has been collected which can be mined for extracting useful information. The later is about using advanced mathematical/statistical technique to build models from the data. Trees in MongoDB. To model hierarchical or nested data relationships, you can use references to implement tree-like structures.
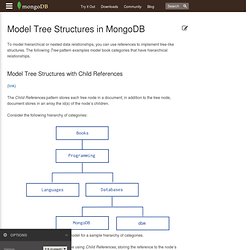
The following Tree pattern examples model book categories that have hierarchical relationships. Model Tree Structures with Child References (link) The Child References pattern stores each tree node in a document; in addition to the tree node, document stores in an array the id(s) of the node’s children. Consider the following hierarchy of categories: Mike Hillyer's Personal Webspace - Managing Hierarchical Data in MySQL. Introduction Most users at one time or another have dealt with hierarchical data in a SQL database and no doubt learned that the management of hierarchical data is not what a relational database is intended for.

The tables of a relational database are not hierarchical (like XML), but are simply a flat list. Adjacency list vs. nested sets: PostgreSQL. This series of articles is inspired by numerous questions asked on the site and on Stack Overflow.
What is better to store hierarchical data: nested sets model or adjacency list (parent-child) model? First, let's explain what all this means. Adjacency list. Storing Hierarchical Data in a Database Article. Now, let’s have a look at another method for storing trees.
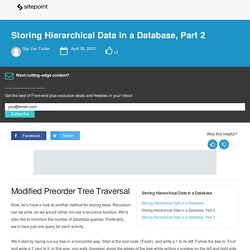
Recursion can be slow, so we would rather not use a recursive function. We’d also like to minimize the number of database queries. Preferably, we’d have just one query for each activity. We’ll start by laying out our tree in a horizontal way. Start at the root node (‘Food’), and write a 1 to its left. We’ll call these numbers left and right (e.g. the left value of ‘Food’ is 1, the right value is 18). Before we continue, let’s see how these values look in our table: Note that the words ‘left’ and ‘right’ have a special meaning in SQL. What Every Developer Should Know About Database Scalability. Cassandra Data Modeling Best Practices, Part 1 — eBay Tech Blog. Guidelines for Modeling and Optimizing NoSQL Databases - LaunchAny. eBay Architect Jay Patel recently posted an article about data modeling using the Cassandra data store.

In his article, he breaks down how they modeled their data using Cassandra, how they approached the use of Columns and Column Families, and query optimizations. The post is very detailed and a great read. What I enjoyed most from the article was more of the high-level approach that Jay and his team took. Here are my favorite takeaways from their approach to data modeling and query optimization, that I believe can be applied to any NoSQL database, including Cassandra, MongoDB, Redis, and others. “It’s important to understand and start with entities and relationships…” Jay reminds us that we must first understand the problem domain, model the entities involved, and the relationships between the data. “…then continue modeling around query patterns by de-normalizing and duplicating.” You cannot optimize your data model until you understand how you will be accessing it. JOINs via denormalization for NoSQL coders, Part 2: Materialized views - Web development blog.
Thomas Wanschik on September 27, 2010 In part 1 we discussed a workaround for JOINs on non-relational databases using denormalization in cases for which the denormalized properties of the to-one side don't change.

In this post we'll show one way to handle JOINs for mutable properties of the to-one side i.e. properties of users. Let's summarize our current situation: We have users (the to-one side) and their photos (the to-many side)Photos contain their users' gender in order to use it in queries which would need JOINs otherwise It's obvious that a solution for the problem of mutable properties on the to-one side has to keep denormalized properties up to date i.e. each time the user changes his/her gender (or more likely her hair color ;) we have to go through all of the user's photos and update the photos' denormalized gender. Background tasks to the rescue One way to solve the update-problem is to start a background task each time a user changes his/her gender. Materialized views. NoSQL Data Modeling Techniques « Highly Scalable Blog.
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency.

This aspect of NoSQL is well-studied both in practice and theory because specific non-functional properties are often the main justification for NoSQL usage and fundamental results on distributed systems like the CAP theorem apply well to NoSQL systems. What the heck are you actually using NoSQL for? It's a truism that we should choose the right tool for the job.
Everyone says that. And who can disagree? The problem is this is not helpful advice without being able to answer more specific questions like: What jobs are the tools good at? Will they work on jobs like mine?