
Stereo_Sceneparsing.pdf. Eccv12_surface. Iccv13_support.pdf. Eth_biwi_00648.pdf. Road_bmvc09.pdf. Web Authentication Redirect. Stereo_bmvc10.pdf. Max-Planck-Institut für Informatik: Sequential Bayesian Model Update under Structured Scene Prior. Valentin_Mesh_Based_Semantic_2013_CVPR_paper.pdf. Research.microsoft.com/en-us/um/people/pkohli/papers/kks_iccv2013.pdf. Yuchao Dai. Ijcv14a.pdf. Nips_2011.pdf. SPME13_ccadena. Nips_2011.pdf. Your college major is a pretty good indication of how smart you are. Twelve grey towers rise up from the fields of wheat and barley near the village of Drax in North Yorkshire.
As you approach, the oak and ash trees that line the road briefly obscure the cooling stacks and their plumes of steam. Then you round a corner and there they are, looming over you, dwarfing everything around them, like a child’s illustration of a belching power station. But Drax, the biggest power plant in England, isn’t the coal-hungry beast it once was. Half of the plant continues to run on fossilized carbon, and the other half has been converted, in a multi-million pound project, to burn biomass—pellets made from wood. Drax is trying to ensure its survival by moving away from fossil fuel and towards a technology that, it says, is more sustainable.
Drax’s conversion, while allowing it to sidestep closure, has opened it up to a whole new set of pressures. Big biomass. Hermans-icra-2014.pdf. Xren_cvpr12_scene_labeling.pdf. 1301.3572. Reza.pdf. ICRA_2014_Mueller.pdf. Xren_cvpr12_scene_labeling.pdf. Hermans-icra-2014.pdf. Ijcv14a.pdf. SchwingEtAl_ICCV2013.pdf.
Scene Parsing with Deep Convolutional Networks. David Grangier. Iccv13_support.pdf. p51.pdf. Indoor scene segmentation using a structured light sensor. GuptaArbelaezMalikCVPR13.pdf. Projects - Yibiao Zhao. Image Parsing via Stochastic Scene Grammar - Yibiao Zhao. Alexander Hermans — Computer Vision Group. Masterthesis.pdf. Estimating the 3D Layout of Indoor Scenes and its Clutter from Depth Sensors. In this paper we propose an approach to jointly estimate the layout of rooms as well as the clutter present in the scene using RGB-D data.
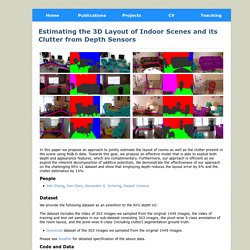
Towards this goal, we propose an effective model that is able to exploit both depth and appearance features, which are complementary. Furthermore, our approach is efficient as we exploit the inherent decomposition of additive potentials. We demonstrate the effectiveness of our approach on the challenging NYU v2 dataset and show that employing depth reduces the layout error by 6% and the clutter estimation by 13%. People Jian Zhang, Kan Chen, Alexander G. Dataset We provide the following dataset as an extention to the NYU depth V2: The dataset includes the index of 303 images we sampled from the original 1449 images, the index of training and test set samples in our sub-dataset consisting 303 images, the pixel-wise 5-class annotation of the room layout, and the pixel-wise 6-class (including clutter) segmentation ground truth.
Code and Data Contact News. ICCV13DepthLayout.pdf. RMRC: Reconstruction Meets Recognition Challenge. For any questions, contact nathan (dot) silberman (at) gmail (dot) com We employ the NYU Depth V2 and Sun3D datasets to define the training data for the RMRC 2014 indoor challenges.
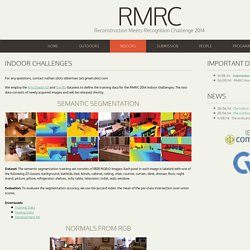
The test data consists of newly acquired images and will be released shortly. Dataset: The semantic segmentation training set consists of 1800 RGB-D images. Each pixel in each image is labeled with one of the following 23 classes: background, bathtub, bed, blinds, cabinet, ceiling, chair, counter, curtain, desk, dresser, floor, night stand, picture, pillow, refrigerator, shelves, sofa, table, television, toilet, wall, window.
Evaluation: To evaluate the segmentation accuracy, we use the Jaccard index: the mean of the per-class intersection over union scores. Downloads: Dataset: The Normals from RGB dataset consists of 4105 RGB and surface normal pairs. Dataset: The depth from RGB dataset consists of 4105 RGB and Depth pairs. Dataset: The instance segmentation dataset consists of 1449 RGB and Depth frames. Tombone's computer vision blog: October 2009. In this post, I want to discuss what the term "segmentation-driven object recognition" means to me.
While segmentation-only and object recognition-only research papers are ubiquitous in vision conferences (such as CVPR , ICCV, and ECCV), a new research direction which uses segmentation for recognition has emerged. Many researchers pushing in this direction are direct descendants of the great J. Malik such as Belongie, Efros, Mori, and many others. The best example of segmentation-driven recognition can be found in Rabinovich's Objects in Context paper. The basic idea in this paper is to compute multiple stable segmentations of an input image using Ncuts and use a dense probabilistic graphical model over segments (combining local terms and segment-segment context) to recognize objects inside those regions.
Segmentation-only research focuses on the actual image segmentation algorithms -- where the output of a segmentation algorithm is a partition of a 2D image into contiguous regions. Martial Hebert homepage. Indoor Scene Understanding. Exploring-High-Level-Plane-Primitives-for-Indoor-3D-REconstruction-with-Hand-held-RGB-D-Cameras.pdf. Indoor scene parsing - Google Search. Scene_functionality_cvpr2013.pdf. Basic level scene understanding: categories, attributes and structures. 1.
Introduction The ability to understand a 3D scene depicted in a static 2D image goes to the very heart of the computer vision problem. By “scene” we mean a place in which a human can act within or navigate. What does it mean to understand a scene? There is no universal answer as it heavily depends on the task involved, and this seemingly simple question hides a lot of complexity. The dominant view in the current computer vision literature is to name the scene and objects present in an image.
What is the ultimate goal of computational scene understanding? Therefore, we propose a set of goals that are suitable for the current state of research in computer vision that are not too simplistic nor challenging and lead to a natural representation of scenes. Cornell Personal Robotics: Code and Data. Mobile Robotics Group. This paper is about the autonomous acquisition of detailed 3D maps of a-priori unknown environments using a stereo camera – it is about choosing where to go.
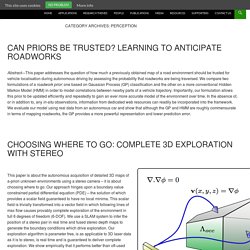
Our approach hinges upon a boundary value constrained partial differential equation (PDE) – the solution of which provides a scalar field guaranteed to have no local minima. This scalar field is trivially transformed into a vector field in which following lines of max flow causes provably complete exploration of the environment in full 6 degrees of freedom (6-DOF). We use a SLAM system to infer the position of a stereo pair in real time and fused stereo depth maps to generate the boundary conditions which drive exploration. Our exploration algorithm is parameter free, is as applicable to 3D laser data as it is to stereo, is real time and is guaranteed to deliver complete exploration.
We show empirically that it performs better than oft-used frontier based approaches and demonstrate our system working with real and simulated data. Tombone's computer vision blog: June 2013. June is that wonderful month during which computer vision researchers, students, and entrepreneurs go to CVPR -- the premier yearly Computer Vision conference.
Whether you are presenting a paper, learning about computer vision, networking with academic colleagues, looking for rock-star vision experts to join your start-up, or looking for rock-star vision start-ups to join, CVPR is where all of the action happens! If you're not planning on going, it is not too late! The Conference starts next week in Portland, Oregon. There are lots of cool papers at CVPR, many which I have already studied in great detail, and many others which I will learn about next week. I will write about some of the cool papers/ideas I encounter while I'm at CVPR next week. Martial Hebert homepage.
4236-image-parsing-with-stochastic-scene-grammar.pdf. Porcupine Tree - Anesthetize.