
Lossless data compression. Lossless compression is a class of data compression algorithms that allows the original data to be perfectly reconstructed from the compressed data.
By contrast, lossy compression permits reconstruction only of an approximation of the original data, though this usually improves compression rates (and therefore reduces file sizes). Lossless compression techniques[edit] Most lossless compression programs do two things in sequence: the first step generates a statistical model for the input data, and the second step uses this model to map input data to bit sequences in such a way that "probable" (e.g. frequently encountered) data will produce shorter output than "improbable" data. There are two primary ways of constructing statistical models: in a static model, the data is analyzed and a model is constructed, then this model is stored with the compressed data. Lossless compression methods may be categorized according to the type of data they are designed to compress. Lossy compression.
Low compression (84% less information than uncompressed PNG, 9.37 KB) Medium compression (92% less information than uncompressed PNG, 4.82 KB) High compression (98% less information than uncompressed PNG, 1.14 KB) In information technology, "lossy" compression is a data encoding method that compresses data by discarding (losing) some of it.
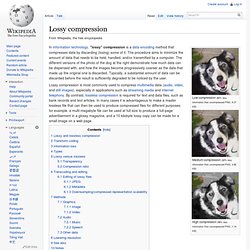
The procedure aims to minimize the amount of data that needs to be held, handled, and/or transmitted by a computer. The different versions of the photo of the dog at the right demonstrate how much data can be dispensed with, and how the images become progressively coarser as the data that made up the original one is discarded. Information theory. Overview[edit] The main concepts of information theory can be grasped by considering the most widespread means of human communication: language.
Two important aspects of a concise language are as follows: First, the most common words (e.g., "a", "the", "I") should be shorter than less common words (e.g., "roundabout", "generation", "mediocre"), so that sentences will not be too long. Such a tradeoff in word length is analogous to data compression and is the essential aspect of source coding. Second, if part of a sentence is unheard or misheard due to noise — e.g., a passing car — the listener should still be able to glean the meaning of the underlying message.