
Www.javageneration.com/wp-content/uploads/2010/05/Cassandra_DataModel_CheatSheet.pdf. Installation:Source. You probably don't want to build from source For most users, it is recommended that you follow the QuickStart guide relevant to your platform, and install pre-built binaries.
These instructions are recommended for developers interested in building from source. These are not upgrade instructions! Attempting to build a newer version of OpenNMS from source on top of an existing install is not supported. If you are upgrading, back up your data and configs and do a fresh install. Applicable versions Getting the source Follow the instructions in the referenced wiki page to install needed files and to download a local copy of the OpenNMS source code. JMX Config Tool. The JmxConfigTool provides a fast and easy way to generate a proper “jmx-datacollection-config” from a running Java application.
Based on the generated configuration file it can also provide a set of “snmp-graph” configurations. The JmxConfigTool offers two modes: Jmx Mode The “Jmx mode” generates an “jmx-datacollection-config” file to provide all relevant configurations to collect metrics from a Java Application and/or a Java Virtual Machine. The network connection to the JVM and the running Java Application is RMI based and can provide credentials. Overview of JmxConfigTool. Schema in Cassandra 1.1. The evolution of schema in Cassandra When Cassandra was first released several years ago, it followed closely the data model outlined in Google’s Bigtable paper (with the notable addition of SuperColumns — more on these later): ColumnFamilies grouping related columns needed to be defined up-front, but column names were just byte arrays interpreted by the application.
It would be fair to characterize this early Cassandra data model as “schemaless.” However, as systems deployed on Cassandra grew and matured, lack of schema became a pain point. The Schema Management Renaissance in Cassandra 1.1. The code that handles schema changes has recently undergone its second major rewrite, which could respectfully be called its renaissance.
The first major rewrite added online schema changes back in Cassandra 0.7, but it had some weaknesses: Schema updates were ordered, and new members of the cluster had to rebuild the schema in that same order, one update at a time. For a cluster with many (thousands) of schema changes, this could add substantial time to bringing new nodes online.
Update ordering also meant that simultaneous updates could cause the infamous schema disagreement errors, with some nodes applying one change first, and other nodes, the other change. Thus, schema was assumed to be relatively static; applications were discouraged from using temporary columnfamilies or otherwise adjusting schema at runtime. Eclipse and OpenNMS. Developing OpenNMS with Eclipse Eclipse 3.5 (or higher) is the recommended install to use for Eclipse.
The easiest thing to do is download Eclipse IDE for Java EE Developers. Do not use the eclipse provided by your distribution (Ubuntu 10.04's Eclipse is broken for instance), it's probably patched and some plugins won't install properly. I know you feel dirty installing applications outside of your favorite package mananger... Code Conventions First, you'll want to configure Eclipse to use the OpenNMS code conventions. Install Eclipse Plugins. Installation:Debian. This tutorial covers installation of OpenNMS on Debian, and Debian-derived distributions like Ubuntu.
This page was tested with: * OpenNMS 1.12.1 on Ubuntu 12.04.3 LTS 64-bit Select Your Release and Distribution In order to tailor this tutorial to your distribution, please specify the release you decided upon previously, as well as your distribution version: Hint: Please make sure you have JavaScript activated in your browser to have a more convenient wiki page for your linux distribution. Release in OpenNMS means: stable, testing, unstable, snapshot Configure APT Adding a Repository. Developing with Git. As of January 1, 2010, OpenNMS is now using Git as its primary SCM.
Browsing Git You can browse our Git repository at GitHub. Install the Git source code management tool Install Git as appropriate for your platform. On Debian/Ubuntu systems, the following command will install Git. sudo apt-get install git Getting OpenNMS by forking the GitHub repository. DataModel. Cassandra is a partitioned row store, where rows are organized into tables with a required primary key.

The first component of a table's primary key is the partition key; within a partition, rows are clustered by the remaining columns of the PK. Other columns may be indexed independent of the PK. This allows pervasive denormalization to "pre-build" resultsets at update time, rather than doing expensive joins across the cluster. Cassandra at Twitter - Distributed Counters. Inbox - pulasthi911. Counters in Cassandra. Advanced Time Series with Cassandra. Cassandra is an excellent fit for time series data, and it’s widely used for storing many types of data that follow the time series pattern: performance metrics, fleet tracking, sensor data, logs, financial data (pricing and ratings histories), user activity, and so on.

A great introduction to this topic is Kelley Reynolds’ Basic Time Series with Cassandra. If you haven’t read that yet, I highly recommend starting with it. This post builds on that material, covering a few more details, corner cases, and advanced techniques. Indexes vs Materialized Views When working with time series data, one of two strategies is typically employed: either the column values contain row keys pointing to a separate column family which contains the actual data for events, or the complete set of data for each event is stored in the timeline itself.
The top column family contains only a timeline index; the bottom, the actual data for the events. Cassandra-user - Cassandra for Ad-hoc Aggregation and formula calculation. Nice email Dan.
Understanding the Cassandra Data Model. The Cassandra data model is a schema-optional, column-oriented data model.
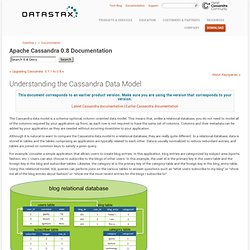
This means that, unlike a relational database, you do not need to model all of the columns required by your application up front, as each row is not required to have the same set of columns. Columns and their metadata can be added by your application as they are needed without incurring downtime to your application. Cassandra NYC 2011 Data Modeling. Basic Time Series with Cassandra. One of the most common use cases for Cassandra is tracking time-series data.
Server log files, usage, sensor data, SIP packets, stuff that changes over time. For the most part this is a straight forward process but given that Cassandra has real-world limitations on how much data can or should be in a row, there are a few details to consider. The most basic and intuitive way to go about storing time-series data is to use a column family that has TimeUUID columns (or Long if you know that no two entries willhappen at the same timestamp), use the name of the thing you are monitoring as the row_key (server1-load for example), column_name as the timestamp, and the column_value would be the actual value of the thing (0.75 for example):