
Apply Magic Sauce - Prediction API - TPTP. The TPTP (Thousands of Problems for Theorem Provers) is a library of test problems for automated theorem proving (ATP) systems.

The TPTP supplies the ATP community with: A comprehensive library of the ATP test problems that are available today, in order to provide an overview and a simple, unambiguous reference mechanism. A comprehensive list of references and other interesting information for each problem. The LEDA User Manual User Manual. The Algorithm Design Manual Senond Edition eBook Free Download - eBook-Daraz. The Algorithm Design Manual Senond Edition eBook Free Download Introduction: Most expert developers that I’ve experienced are not all around arranged to handle calculation plan issues.
This is a compassion, in light of the fact that the procedures of calculation configuration frame one of the center down to earth innovations of software engineering. Outlining right, productive, and implementable calculations for genuine issues obliges access to two unmistakable collections of learning: Li. According to a Content Marketing Institute report, 86% of B2B companies use content marketing, but only 28% say that their efforts are effective.

However, there is little doubt about the effectiveness of content marketing as a strategy to drive targeted traffic and generate high-quality leads. This implies that something along the execution can be optimized to achieve content marketing’s full potential. Top 10 data mining algorithms in plain English. Today, I’m going to explain in plain English the top 10 most influential data mining algorithms as voted on by 3 separate panels in this survey paper.
Once you know what they are, how they work, what they do and where you can find them, my hope is you’ll have this blog post as a springboard to learn even more about data mining. What are we waiting for? Let’s get started! Update 16-May-2015: Thanks to Yuval Merhav and Oliver Keyes for their suggestions which I’ve incorporated into the post. Top 10 data mining algorithms in plain R. Knowing the top 10 most influential data mining algorithms is awesome.
Knowing how to USE the top 10 data mining algorithms in R is even more awesome. That’s when you can slap a big ol’ “S” on your chest… …because you’ll be unstoppable! B+ tree. A simple B+ tree example linking the keys 1–7 to data values d1-d7.
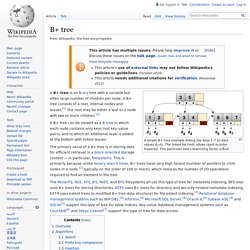
The linked list (red) allows rapid in-order traversal. This particular tree's branching factor is A B+ tree is an N-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. First Order Inductive Learner. In machine learning, First Order Inductive Learner (FOIL) is a rule-based learning algorithm.
Background[edit] Algorithm[edit] Supprimer un noeud dans un arbre Binaire. 27 Free Data Mining Books - DataOnFocus. As you know, here at DataOnFocus we love to share information, specially about data sciences and related subjects.

And what is one of the best ways to learn about a specific topic? Reading a book about it, and then practice with the fresh knowledge you acquired. And what is better than increase your knowledge by studying a high quality book about a subject you like? 50+ Data Science and Machine Learning Cheat Sheets. Gear up to speed and have Data Science & Data Mining concepts and commands handy with these cheatsheets covering R, Python, Django, MySQL, SQL, Hadoop, Apache Spark and Machine learning algorithms.

Cheatsheets on Python, R and Numpy, Scipy, Pandas There are thousands of packages and hundreds of functions out there in the Data science world! Top 27 Free Data Analysis Software. 40 Top Free Data Mining Software. RapidMiner - #1 Open Source Predictive Analytics Platform. Computational Urban Design Research Studio.
Laster semester we utilize two kinds of clustering algorithms to do our analyze.

The first one is distance based clustering, the second one is grid based clustering. Although logically they are very similar, both of them are forming clusters based on distances, they are different in doing this, and results can be different. Below is the logic of these 2 algorithms. A. distance based clustering: Graph theory. Refer to the glossary of graph theory for basic definitions in graph theory.
Definitions[edit] Definitions in graph theory vary. The following are some of the more basic ways of defining graphs and related mathematical structures. Graph[edit] Top 10 Data Mining Algorithms, Explained. Top 10 data mining algorithms, selected by top researchers, are explained here, including what do they do, the intuition behind the algorithm, available implementations of the algorithms, why use them, and interesting applications. By Raymond Li. Today, I’m going to explain in plain English the top 10 most influential data mining algorithms as voted on by 3 separate panels in this survey paper.
Once you know what they are, how they work, what they do and where you can find them, my hope is you’ll have this blog post as a springboard to learn even more about data mining. What are we waiting for? Hackathon FUN POEM P3E - cnsc. Pierre Collet, Anna Scius-Bertrand - Terrasses du Numérique (28/06/2013) Hackathon FUN POEM ManHill Optimization - cnsc. MeTA: ModErn Text Analysis : MeTA. Shivon Zilis - Machine Intelligence. Machine Intelligence in the Real World (this pieces was originally posted on Tech Crunch) . I’ve been laser-focused on machine intelligence in the past few years.
Process Mining - Discovery, Conformance and Enhancement of Business Processes - First 5 Chapters by Wil Aalst, van der. Process Mining - Discovery, Conformance and Enhancement of Business Processes - First 5 Chapters by Wil Aalst, van der. Data Mining Survivor: - dmsurvivor. The procedures and applications presented in this book have been included for their instructional value. They have been tested but are the author offer any warranties or representations, nor do they accept any liabilities with respect to the programs and applications. The book, as you see it presently, is a work in progress, and different sections are progressed depending on feedback.
Please send comments, suggestions, updates, and criticisms to Graham.Williams@togaware.com. I hope you find it useful! Togaware: Open Source Solutions and Data Mining. Initiation � l'Algorithmique et � la Programmation. Statistical Mechanics: Algorithms and Computations - École normale supérieure. About the Course This course discusses the computational approach in modern physics in a clear yet accessible way.
Individual modules contain in-depth discussions of algorithms ranging from basic enumeration methods to cutting-edge Markov-chain techniques. Data Mining - Autumn 2005. SPMF: A Java Open-Source Data Mining Library.