
Exemples de réseaux de neurones et de modèles non-linéaires avec Neuro One de Netral. Wikiwix's cache. Noyau (statistiques) Un article de Wikipédia, l'encyclopédie libre.
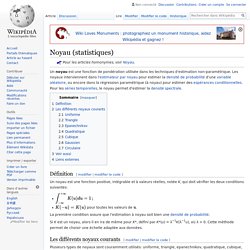
Pour les articles homonymes, voir Noyau. Un noyau est une fonction de pondération utilisée dans les techniques d'estimation non-paramétrique. Les noyaux interviennent dans l'estimateur par noyau pour estimer la densité de probabilité d'une variable aléatoire, ou encore dans la régression paramétrique (à noyau) pour estimer des espérances conditionnelles.
Pour les séries temporelles, le noyau permet d'estimer la densité spectrale. Un noyau est une fonction positive, intégrable et à valeurs réelles, notée K, qui doit vérifier les deux conditions suivantes: pour toutes les valeurs de . La première condition assure que l'estimation à noyau soit bien une densité de probabilité. Si K est un noyau, alors il en ira de même pour K*, défini par K*(u) = λ−1K(λ−1u), où λ > 0. Plusieurs types de noyaux sont couramment utilisés: uniforme, triangle, epanechnikov, quadratique, cubique, gaussien, et circulaire. Self-Organizing Maps and Growing Neural Gas - Fast Artificial Neural Network Library (FANN) Self-Organizing Maps (SOM) is an unsupervised learning method that uses vector quantization to allow visualization and clustering of data.

It is unsupervised because the only input (besides the parameters of the algorithm) is the data itself. In a classification problem, for example, the labels for each data point are not available. One interesting property of the resulting maps is that it is topographically ordered, that is neurons that are closer to each other are more similar than more distant ones. This makes them useful for visualization. The simplest form of SOM consists of a two dimensional rectangular or hexagonal grid of neurons, each of which represents a point in an N dimensional space. The simplest SOM works like so: For each training data, a node from the existing network that is closest (according to some distance measure, in FANN Euclidean distance) is assigned as the winning node. MasterThesisProj. Top 20 Python Machine Learning Open Source Projects, updated.
Continuing analysis from last year: Top 20 Python Machine Learning Open Source Projects, this year KDnuggets bring you latest top 20 Python Machine Learning Open Source Projects on Github.
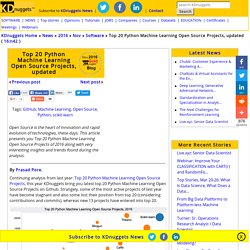
Strangely, some of the most active projects of last year have become stagnant and also some lost their position from top 20 (considering contributions and commits), whereas new 13 projects have entered into top 20. Top 20 Python Machine Learning Open Source Projects 2016. Scikit-learn is simple and efficient tools for data mining and data analysis, accessible to everybody, and reusable in various context, built on NumPy, SciPy, and matplotlib, open source, commercially usable – BSD license. Commits: 21486, Contributors: 736, Github URL: Scikit-learnTensorflow was originally developed by researchers and engineers working on the Google Brain Team within Google’s Machine Intelligence research organization. Happy Open Sourcing and Knowledge Sharing! Related: Deep Learning Tutorials — DeepLearning 0.1 documentation. GitHub - rushter/MLAlgorithms: Minimal and clean examples of machine learning algorithms.
FUTURS DE L'INTELLIGENCE ARTIFICIELLE (Yann LeCun - Jean Ponce - Alexandre Cadain) SophiaConf2016 M. GORNER (Google) Tensorflow et l’apprentissage profond. Deep Learning Demystified. Cours sur l'apprentissage automatique. Notes de cours sur l'apprentissage automatique supervisé : cadre PAC, boosting, bagging et méthodes d'ensemble, méthodologie, etc.

Motivations L'apprentissage automatique intervient dans des processus de décision et doit permettre de répondre à des questions aussi diverses que : mon patient aura-t-il un accident cardio-vasculaire dans les cinq ans à venir ? Quel sera le résultat du prochain Marseille - Bastia ? La molécule que je désire commercialiser est-elle cancérigène ? Notons que des experts humains peuvent être consultés sur bon nombre de ces questions (un médecin pour déterminer le risque encouru par un patient, un amateur de football pour le résultat du match, etc.).
Cette motivation a conduit à la définition de systèmes experts (ou systèmes à base de connaissance) : ceux-ci sont capables de mener un raisonnement à partir de faits décrivant le problème à résoudre et d'une expertise sous forme de règles. Les types de réponse La représentation des exemples Le test de subsomption. Free Deep Learning Textbook Finished. Data science a machine learning tour (french) XebiConFr15 - Les algorithmes du machine learning. Nipdev 17 – Une introduction au Machine Learning avec Vincent Heuschling. Podcast: Téléchargement Dans ce numéro, Vincent Heuschling nous parle de Machine Learning et nous en décrit les principes de base.
Qu’est ce que le Machine LearningDifférence ML et stats (descriptives, Inférences, Bayes)Data driven décision, dépasser le cadre de la Business Intelligence traditionnellepourquoi c’est Indispensable qd on a beaucoup de donnéesA quoi ça sert (rapidement)Web – PersonnalisationWeb – Recommandation à lire : à ecouter : prédictifsSegmentation marketingComment ça marcheDifférences entre Supervisé et Non-superviséClassificationRegressionSimilarité (recommenders)ClusteringCo-occurencePrédictionsOverfittingPanorama des outils disponibles :R avec Rstudio => l’option du statisticien, c’est pas à la base un outil de développeur.
Deep learning - Yann LeCun, à l'USI.
Cours wira. Harold Christopher Burger.