
Stylometry. The Signature Stylometric System. The aim of this website is to highlight the many strong links between Philosophy and Computing, for the benefit of students of both disciplines: For students of Philosophy who are seeking ways into formal Computing, learning by discovery about programming, how computers work, language processing, artificial intelligence, and even conducting computerised thought experiments on philosophically interesting problems such as the evolution of co-operative behaviour.
For students of Computing who are keen to see how their technical abilities can be applied to intellectually exciting and philosophically challenging problems. The links along the top of these web pages lead to the main sections of the website (click here for the next page in the "Home" section). Top 11 Free Software for Text Analysis, Text Mining, Text Analytics - Predictive Analytics Today.
Topicalizer - The tool for topic extraction, text analysis and abstract generation. Clustify - Document Clustering Software - Cluster documents for organization or taxonomy development. Phrase Detectives - The AnaWiki annotation game. Tests Document Readability. Visualizing Topic Models - ChaneyBlei2012.pdf. National Centre for Text Mining — Text Mining Tools and Text Mining Services. Text analysis, wordcount, keyword density analyzer, prominence analysis.
Linguistics and the Book of Mormon. DiscoverText - A Text Analytic Toolkit for eDiscovery and Research. Graphing the history of philosophy « Drunks&Lampposts. A close up of ancient and medieval philosophy ending at Descartes and Leibniz If you are interested in this data set you might like my latest post where I use it to make book recommendations.
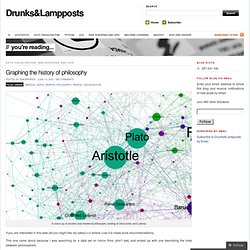
This one came about because I was searching for a data set on horror films (don’t ask) and ended up with one describing the links between philosophers. To cut a long story very short I’ve extracted the information in the influenced by section for every philosopher on Wikipedia and used it to construct a network which I’ve then visualised using gephi It’s an easy process to repeat. It could be done for any area within Wikipedia where the information forms a network.
First I’ll show why I think it’s worked as a visualisation. Jana_SI08-poster-final.pdf (Objet application/pdf) Online Text Analysis Tool. WordCounter. Zipf's law. Zipf's law /ˈzɪf/, an empirical law formulated using mathematical statistics, refers to the fact that many types of data studied in the physical and social sciences can be approximated with a Zipfian distribution, one of a family of related discrete power law probability distributions.
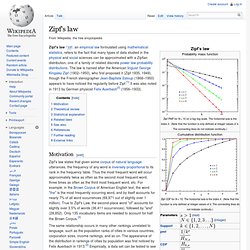
The law is named after the American linguist George Kingsley Zipf (1902–1950), who first proposed it (Zipf 1935, 1949), though the French stenographer Jean-Baptiste Estoup (1868–1950) appears to have noticed the regularity before Zipf.[1] It was also noted in 1913 by German physicist Felix Auerbach[2] (1856–1933). Motivation[edit] Zipf's law states that given some corpus of natural language utterances, the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, etc. Theoretical review[edit] WORDCOUNT / Tracking the Way We Use Language / JGAAP.
Concordance: software for concordancing and text analysis. Untitled. Mining Data-text-web. Lexico Web Page (downloadable app for the PC) Cédric Lamalle, William Martinez, Serge Fleury, André Salem Lexico3 est réalisé par l’équipe universitaire SYLED-CLA2T.
Ce logiciel fait l’objet d’une diffusion commerciale. Si vous êtes un chercheur isolé, vous pouvez vous en servir momentanément, pour vos travaux personnels. Si par contre votre laboratoire, votre entreprise, peut acquérir ce logiciel, cela nous aidera à le développer. A votre demande, nous vous enverrons une facture émise par l'agent comptable de l'Université Paris 3 Sorbonne nouvelle, en commençant par une facture "pro forma" si vous le souhaitez (précisez à qui elle doit être adressée).
English Version. STREMOR : natural language understanding through heuristics. BigSee < Main < WikiTADA. This page is for the SHARCNET and TAPoR text visualization project.

Note that it is a work in progress as this is an ongoing project. At the University of Alberta we picked up the project and gave a paper at the Chicago Colloquium on Digital Humanities and Computer Science with the title | The Big See: Large Scale Visualization. The Big See is an experiment in high performance text visualization. Semantic Search Engine and Text Analysis. Parsing. Within computational linguistics the term is used to refer to the formal analysis by a computer of a sentence or other string of words into its constituents, resulting in a parse tree showing their syntactic relation to each other, which may also contain semantic and other information.
The term is also used in psycholinguistics when describing language comprehension. In this context, parsing refers to the way that human beings analyze a sentence or phrase (in spoken language or text) "in terms of grammatical constituents, identifying the parts of speech, syntactic relations, etc. " [2] This term is especially common when discussing what linguistic cues help speakers to interpret garden-path sentences.
Human languages[edit] Traditional methods[edit] Parsing was formerly central to the teaching of grammar throughout the English-speaking world, and widely regarded as basic to the use and understanding of written language. The Stanford NLP (Natural Language Processing) Group. About | Citing | Questions | Download | Included Tools | Extensions | Release history | Sample output | Online | FAQ A natural language parser is a program that works out the grammatical structure of sentences, for instance, which groups of words go together (as "phrases") and which words are the subject or object of a verb.
Probabilistic parsers use knowledge of language gained from hand-parsed sentences to try to produce the most likely analysis of new sentences. These statistical parsers still make some mistakes, but commonly work rather well. Their development was one of the biggest breakthroughs in natural language processing in the 1990s. Les outils de Text Mining - Les critères de choix. Text Analytics. Analysis. Jean Lievens: Wikinomics Model for Value of Open Data Categories: Analysis,Architecture,Balance,Citizen-Centered,Data,Design,Graphics,ICT-IT,Knowledge,Policies-Harmonization,Processing,Strategy-Holistic Coherence Jean Lievens A visual model showing the value of open data Prof.
Robert Appleton of Ryerson University recently told me: “In most fields, the language [of communication] is still dominated by words and numbers.” Visualize Business Models I bought the book Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers [72 slides free online at SlideShare] by Alexander Osterwalder. Second, the book itself has a new business model.