
Welcome to polyglot’s documentation! — polyglot 16.07.04 documentation. A propos de JeuxDeMots. Informations sur l'état du jeu Il y a 199597 parties en attente. 1481433 parties ont été jouées depuis le début.
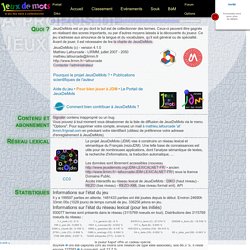
Environ 24690h 33min 00s (1029 jours) de temps cumulé de jeu. 336256 jetons en jeu. Informations sur l'état du réseau lexical (pour les initiés) 930077 termes sont présents dans le réseau (3115769 noeuds en tout). Distributions des 3115769 noeuds du réseau : ont été capturés (ont au moins une relation de type idée associée), soit 86.3 %. À conquérir, soit 13.7 %. National Centre for Text Mining — Text Mining Tools and Text Mining Services. JEP-TALN-RECITAL 2016. Documentation LaTeX / Texmaker. Arborator. French stemming algorithm. Letters in French include the following accented forms, â à ç ë é ê è ï î ô û ù The following letters are vowels: a e i o u y â à ë é ê è ï î ô û ù Assume the word is in lower case.

Then put into upper case u or i preceded and followed by a vowel, and y preceded or followed by a vowel. u after q is also put into upper case. (The upper case forms are not then classed as vowels — see note on vowel marking.) If the word begins with two vowels, RV is the region after the third letter, otherwise the region after the first vowel not at the beginning of the word, or the end of the word if these positions cannot be found. For example, SONDY - University of Lyon 2. About SONDY SONDY (SOcial Network DYnamics) is an open source software written in Java for collecting, analyzing, and mining data generated by social media.

Its main focus is on event detection and influence analysis. The goal of this software is to provide a way to identify events to which people react, and to identify the most influential people inside these events. To this end, SONDY implements several state-of-the-art algorithms and various visualizations that allow for an efficient exploration of the data. SONDY also offers data preprocessing functionalities and features an advanced user interface. Apache OpenNLP - Welcome to Apache OpenNLP. An Gramadóir. Kevin P.

Scannell Summary This is the home page for An Gramadóir, an open source grammar checking engine. It is intended as a platform for the development of sophisticated natural language processing tools for languages with limited computational resources. It is currently implemented for the Irish language (Gaeilge); this is, to the best of my knowledge, the first grammar checker developed for any minority language. LingPipe Home. How Can We Help You?
Get the latest version: Free and Paid Licenses/DownloadsLearn how to use LingPipe: Tutorials Get expert help using LingPipe: Services Join us on Facebook What is LingPipe? LingPipe is tool kit for processing text using computational linguistics. LingPipe is used to do tasks like: Find the names of people, organizations or locations in newsAutomatically classify Twitter search results into categoriesSuggest correct spellings of queries To get a better idea of the range of possible LingPipe uses, visit our tutorials and sandbox.
Architecture LingPipe's architecture is designed to be efficient, scalable, reusable, and robust. Latest Release: LingPipe 4.1.2. GATE.ac.uk - index.html. Wapiti - A simple and fast discriminative sequence labelling toolkit. Apache UIMA - Apache UIMA. Natural Language Toolkit — NLTK 3.0 documentation. ORTOLANG. ORTOLANG est un équipement d’excellence validé dans le cadre des investissements d’avenir.
Son but est de proposer une infrastructure en réseau offrant un réservoir de données (corpus, lexiques, dictionnaires, etc.) et d’outils sur la langue et son traitement clairement disponibles et documentés qui : permette, au travers d’une véritable mutualisation, à la recherche sur l’analyse, la modélisation et le traitement automatique de notre langue de se hisser au meilleur niveau international; facilite l’usage et le transfert des ressources et outils mis en place au sein des laboratoires publics vers les partenaires industriels, en particulier vers les PME qui souvent ne peuvent pas se permettre de développer de telles ressources et outils de traitement de la langue compte tenu de leurs coûts de réalisation; valorise le français et les langues de France à travers un partage des connaissances sur notre langue accumulées par les laboratoires publics.
Revue TAL. QSR - Logiciel NVivo pour la recherche qualitative – de l’analyse de contenu et de l’évaluation jusqu’à l’étude de marché. Tesseract-ocr - An OCR Engine that was developed at HP Labs between 1985 and 1995... and now at Google. FileFormat.Info · The Digital Rosetta Stone. Plagramme.fr. Projet Textométrie. Site web Alpage : Logiciels. NooJ. Laurence Anthony's AntConc. Semantria Web Demo. Alchemy Demo. The Stanford NLP (Natural Language Processing) Group. About | Getting started | Questions | Mailing lists | Download | Extensions | Models | Online demo | Release history | FAQ About Stanford NER is a Java implementation of a Named Entity Recognizer.
Named Entity Recognition (NER) labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names. It comes with well-engineered feature extractors for Named Entity Recognition, and many options for defining feature extractors. Included with the download are good named entity recognizers for English, particularly for the 3 classes (PERSON, ORGANIZATION, LOCATION), and we also make available on this page various other models for different languages and circumstances, including models trained on just the CoNLL 2003 English training data. Stanford NER is also known as CRFClassifier.
The CRF code is by Jenny Finkel. Jenny Rose Finkel, Trond Grenager, and Christopher Manning. 2005. Getting started This NER system requires Java 1.8 or later.