
Mikeaddison93/gephi. Knuth: The Stanford GraphBase. By Donald E.

Knuth (New York: ACM Press, 1994), viii+576pp. Apache Giraph (Incubating) Skip to end of metadataGo to start of metadata Web and online social graphs have been rapidly growing in size and scale during the past decade.
In 2008, Google estimated that the number of web pages reached over a trillion. Online social networking and email sites, including Yahoo! , Google, Microsoft, Facebook, LinkedIn, and Twitter, have hundreds of millions of users and are expected to grow much more in the future. Processing these graphs plays a big role in relevant and personalized information for users, such as results from a search engine or news in an online social networking site. Graph processing platforms to run large-scale algorithms (such as page rank, shared connections, personalization-based popularity, etc.) have become quite popular. Giraph follows the bulk-synchronous parallel model relative to graphs where vertices can send messages to other vertices during a given superstep. To get started, visit: Quick Start Guide. Giraph - Welcome To Apache Giraph!
Dato Core™ Open Source. SFrame™, the fast, scalable engine of GraphLab Create™ is now open source.
The SFrame project provides the complete implementation of the following: SFrame SArray SGraph The C++ SDK surface area (gl_sframe, gl_sarray, gl_sgraph) Support for strictly typed columns (int, float, str, datetime), weakly typed columns (schema free lists, dictionaries) as well as specialized types such as Image. Uniform support for missing data. Query optimization and Lazy evaluation. A Python API (SArray, SFrame, SGraph) with an indirect access via an interprocess layer. Giraph - Welcome To Apache Giraph! Practical Neo4j. Neo4j: Cypher – Avoiding the Eager at Mark Needham. Although I love how easy Cypher’s LOAD CSV command makes it to get data into Neo4j, it currently breaks the rule of least surprise in the way it eagerly loads in all rows for some queries even those using periodic commit.
Beware of the eager pipe This is something that my colleague Michael noted in the second of his blog posts explaining how to use LOAD CSV successfully: The biggest issue that people ran into, even when following the advice I gave earlier, was that for large imports of more than one million rows, Cypher ran into an out-of-memory situation.That was not related to commit sizes, so it happened even with PERIODIC COMMIT of small batches. I recently spent a few days importing data into Neo4j on a Windows machine with 4GB RAM so I was seeing this problem even earlier than Michael suggested. Michael explains how to work out whether your query is suffering from unexpected eager evaluation: You can profile queries by prefixing the word ‘PROFILE’.
LOAD CSV into Neo4j quickly and successfully. Posted by Michael Hunger on Jun 25, 2014 in cypher, import | Since version 2.1 Neo4j provides out-of-the box support for CSV ingestion.

The LOAD CSV command that was added to the Cypher Query language is a versatile and powerful ETL tool. It allows you to ingest CSV data from any URL into a friendly parameter stream for your simple or complex graph update operation, that … conversion. Neo4j 2.1 - Graph ETL for Everyone. By Andreas Kollegger | May 29, 2014 It’s an exciting time for Neo4j users and, of course, the Neo4j team as we’re releasing the 2.1 version of Neo4j!
You’ve probably already seen the amazing strides we’ve taken when releasing our 2.0 version at the start of the year, and Neo4j 2.1 continues to improve the user experience while delivering some impressive under-the-hood improvements, and some interesting work on boosting Cypher too. Easy import with ETL features directly in Cypher Graphs are everywhere, but sometimes they’re buried in other systems and legacy databases.
You need to extract the data then bring it into Neo4j to experience its true graph form. To illustrate, consider this small set of fictional Twitter users and their followers: We can easily represent this as a CSV file as follows: (note that the LOAD CSV separator is strictly a comma, not comma and whitespace!) Importing CSV Data into Neo4j. 11.8. Importing CSV files with Cypher - - The Neo4j Manual v2.1.6. This tutorial will show you how to import data from CSV files using LOAD CSV.
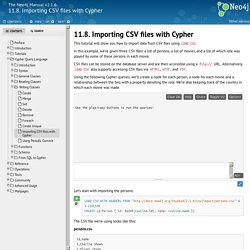
In this example, we’re given three CSV files: a list of persons, a list of movies, and a list of which role was played by some of these persons in each movie. CSV files can be stored on the database server and are then accessible using a URL. Alternatively, LOAD CSV also supports accessing CSV files via HTTPS, HTTP, and FTP. Using the following Cypher queries, we’ll create a node for each person, a node for each movie and a relationship between the two with a property denoting the role. We’re also keeping track of the country in which each movie was made. Import Data Into Neo4j. Structr - Home. Mongraph. Mongraph combines documentstorage database with graph-database relationships.
Experimental. API may change. Dependencies Databases. Polyglot Persistence and Query with Gremlin. February 4, 2013 by Stephen Mallette Complex data storage architectures are not typically grounded to a single database.

In these environments, data is highly disparate, which means that it exists in many forms, is aggregated and duplicated at different levels, and in the worst case, the meaning of the data is not clearly understood. Environments featuring disparate data can present challenges to those seeking to integrate it for purposes of analytics, ETL (Extract-Transform-Load) and other business services. Having easy ways to work with data across these types of environments enables the rapid engineering of data solutions. Some causes for data disparity rise from the need to store data in different database types, so as to take advantage of the specific benefits that each type exposes.
Gremlin is a domain specific language (DSL) for traversing graphs. Developer: Cypher. Blog.benmcmahen. InfluxDB - Open Source Time Series, Metrics, and Analytics Database. MongoGraph Brings Semantic Web Features to MongoDB Developers. MongoGraph from AllegroGraph team brings semantic web features to MongoDB developers.

They implemented a MongoDB interface to AllegroGraph database to give Javascript programmers both joins and the semantic web capabilities. Using this approach JSON objects are automatically translated into triples and both the MongoDB query language and SPARQL work against these objects. Database - Storing a graph in mongodb. Building a Directed Graph with MongoDB.
Using MongoDB as a high performance graph database. Franz Inc. - Semantic Graph and Common Lisp Solutions. Redis_graph 1.0. Package Index > redis_graph > 1.0 Not Logged In Status Nothing to report redis_graph 1.0. Titan Documentation. Weaver. Steve dekorte - projects - open source - vertexdb. VelocityGraph - Graph Database. Titan: Distributed Graph Database. Titan is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. Titan is a transactional database that can support thousands of concurrent users executing complex graph traversals in real time. In addition, Titan provides the following features: Download Titan or clone from GitHub. Read the Titan documentation and join the mailing list. High performance graph analytics. Home - OrientDB Document-Graph NoSQL DatabaseOrientDB Document-Graph NoSQL Database.
OpenLink Software. Neo4j, the World's Leading Graph Database. Mapgraph: MapGraph. Bigdata. Graph database. Graph databases are part of the NoSQL databases created to address the limitations of the existing relational databases. While the graph model explicitly lays out the dependencies between nodes of data, the relational model and other NoSQL database models link the data by implicit connections. Graph databases, by design, allow simple and fast retrieval[citation needed] of complex hierarchical structures that are difficult to model[according to whom?]
In relational systems. ArangoDB - the multi-purpose NoSQL DB. Franz Inc. - Semantic Graph and Common Lisp Solutions.