
Simple Recurrent Network. Since the publication of the original pdp books (Rumelhart et al., 1986; McClelland et al., 1986) and back-propagation algorithm, the bp framework has been developed extensively.

Two of the extensions that have attracted the most attention among those interested in modeling cognition have been the Simple Recurrent Network (SRN) and the recurrent back-propagation (RBP) network. In this and the next chapter, we consider the cognitive science and cognitive neuroscience issues that have motivated each of these models, and discuss how to run them within the PDPTool framework. 7.1.1 The Simple Recurrent Network The Simple Recurrent Network (SRN) was conceived and first used by Jeff Elman, and was first published in a paper entitled Finding structure in time (Elman, 1990). Figure 7.1: The SRN network architecture. An SRN of the kind Elman employed is illustrated in Figure 7.1. Backpropagation. The project describes teaching process of multi-layer neural network employing backpropagation algorithm.
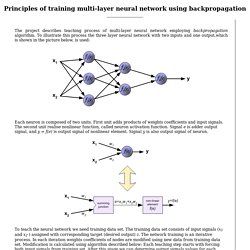
To illustrate this process the three layer neural network with two inputs and one output,which is shown in the picture below, is used: Each neuron is composed of two units. First unit adds products of weights coefficients and input signals. The second unit realise nonlinear function, called neuron activation function. Signal e is adder output signal, and y = f(e) is output signal of nonlinear element.
To teach the neural network we need training data set. Propagation of signals through the hidden layer. Propagation of signals through the output layer. Learning Vector Quantization (LVQ) Next: Support Vector Machines (SVM) Up: Competitive Learning Networks Previous: Self-organizing property of the Learning Vector Quantization (LVQ) LVQ is a supervised learning algorithm based on a set of training vectors with known classes (labeled).

Learning rule. Learning rule or Learning process is a method or a mathematical logic which improves the neural network's performance and usually this rule is applied repeatedly over the network.
It is done by updating the weights and bias levels of a network when a network is simulated in a specific data environment.[1] A learning rule may accept existing condition ( weights and bias ) of the network and will compare the expected result and actual result of the network to give new and improved values for weights and bias. [2] Depending on the complexity of actual model, which is being simulated, the learning rule of the network can be as simple as an XOR gate or Mean Squared Error or it can be the result of multiple differential equations.
The learning rule is one of the factors which decides how fast or how accurate the artificial network can be developed. UFLDL Tutorial - Ufldl. Neural Networks for Machine Learning. About the Course Neural networks use learning algorithms that are inspired by our understanding of how the brain learns, but they are evaluated by how well they work for practical applications such as speech recognition, object recognition, image retrieval and the ability to recommend products that a user will like.
As computers become more powerful, Neural Networks are gradually taking over from simpler Machine Learning methods. They are already at the heart of a new generation of speech recognition devices and they are beginning to outperform earlier systems for recognizing objects in images. The course will explain the new learning procedures that are responsible for these advances, including effective new proceduresr for learning multiple layers of non-linear features, and give you the skills and understanding required to apply these procedures in many other domains.
Recommended Background Programming proficiency in Matlab, Octave or Python. Course Format. Algorithmic composition. Maybe later |Close Thank you!
We will send you a reminder email. Dear readers in Canada, time is running out in 2016 to help Wikipedia. To protect our independence, we'll never run ads. We're sustained by donations averaging about $15. Algorithmic composition is the technique of using algorithms to create music. Algorithms (or, at the very least, formal sets of rules) have been used to compose music for centuries; the procedures used to plot voice-leading in Western counterpoint, for example, can often be reduced to algorithmic determinacy. Some algorithms or data that have no immediate musical relevance are used by composers[1] as creative inspiration for their music.
Models for algorithmic composition[edit] There is no universal method to sort different compositional algorithms into categories. Another way to sort compositional algorithms is to examine the results of their compositional processes. Translational Models[edit] Mathematical models[edit] Knowledge-based systems[edit]