Information retrieval. Information retrieval is the activity of obtaining information resources relevant to an information need from a collection of information resources.
Searches can be based on metadata or on full-text (or other content-based) indexing. Automated information retrieval systems are used to reduce what has been called "information overload". Many universities and public libraries use IR systems to provide access to books, journals and other documents. Web search engines are the most visible IR applications.
Overview[edit] An information retrieval process begins when a user enters a query into the system. An object is an entity that is represented by information in a database. Most IR systems compute a numeric score on how well each object in the database matches the query, and rank the objects according to this value. History[edit] Model types[edit] For effectively retrieving relevant documents by IR strategies, the documents are typically transformed into a suitable representation. Recall[edit] Data mining. Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.[1] Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information (with intelligent methods) from a data set and transform the information into a comprehensible structure for further use.[1][2][3][4] Data mining is the analysis step of the "knowledge discovery in databases" process or KDD.[5] Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.[1] Etymology[edit] In the 1960s, statisticians and economists used terms like data fishing or data dredging to refer to what they considered the bad practice of analyzing data without an a-priori hypothesis.
Data warehouse. Data Warehouse Overview In computing, a data warehouse (DW, DWH), or an enterprise data warehouse (EDW), is a database used for reporting and data analysis.
Integrating data from one or more disparate sources creates a central repository of data, a data warehouse (DW). Data warehouses store current and historical data and are used for creating trending reports for senior management reporting such as annual and quarterly comparisons. The data stored in the warehouse is uploaded from the operational systems (such as marketing, sales, etc., shown in the figure to the right).
The data may pass through an operational data store for additional operations before it is used in the DW for reporting. A data warehouse constructed from integrated data source systems does not require ETL, staging databases, or operational data store databases. A data mart is a small data warehouse focused on a specific area of interest. This definition of the data warehouse focuses on data storage. History[edit] Knowledge extraction. Knowledge extraction is the creation of knowledge from structured (relational databases, XML) and unstructured (text, documents, images) sources.
The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL (data warehouse), the main criteria is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge (reusing identifiers or ontologies) or the generation of a schema based on the source data. Overview[edit] After the standardization of knowledge representation languages such as RDF and OWL, much research has been conducted in the area, especially regarding transforming relational databases into RDF, identity resolution, knowledge discovery and ontology learning.
Examples[edit] XML[edit] Knowledge retrieval. Knowledge Retrieval seeks to return information in a structured form, consistent with human cognitive processes as opposed to simple lists of data items.
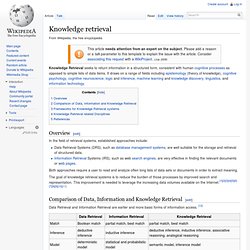
It draws on a range of fields including epistemology (theory of knowledge), cognitive psychology, cognitive neuroscience, logic and inference, machine learning and knowledge discovery, linguistics, and information technology. Overview[edit] Knowledge discovery.