
FREE OCR software: a survey of desktop and online tools. Printing text to paper is done every day; on some occasions however the reverse is needed – getting the original text back from a scanned image or photograph, for further editing and use.
This conversion is named Optical Character Recognition or OCR for short, and it can convert scanned books and documents into editable text, to get editable text from PDFs created via scanning, or even get text from screenshots and images. Free OCR Software - FreeOCR.net the free OCR list - Optical character recognition software. The 3 Best Free OCR Tools To Convert Your Files Back Into Editable Documents. Believe it or not, some people still print documents on physical pieces of paper.
Some open source for OCR, Image recognition, handwriting recognition. How to scan and OCR like a pro with open source tools. With optical character recognition (OCR), you can scan the contents of a document into a single file of editable text.
This article, which focuses on scanning books, describes the steps you need to take to prepare pages for optimal OCR results, and compares various free OCR tools to determine which is the best at extracting the text. First, fire up your distribution's package manager to fetch a few packages and dependencies. Linux OCR Software Comparison. Over the last weeks I spent some time with researching available OCR (Optical Character Recognition) tools for Linux.
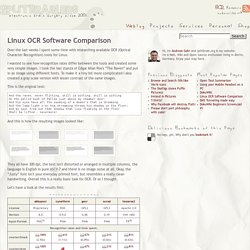
I wanted to see how recognition rates differ between the tools and created some very simple images. I took the last stanza of Edgar Allan Poe's “The Raven” and put in an image using different fonts. To make it a tiny bit more complicated I also created a gray scale version with lesser contrast of the same images. This is the original text: And the raven, never flitting, still is sitting, still is sitting On the pallid bust of Pallas just above my chamber door; And his eyes have all the seeming of a demon's that is dreaming, And the lamp-light o'er him streaming throws his shadow on the floor; And my soul from out that shadow that lies floating on the floor Shall be lifted - nevermore!
How to Scan a Letter Document Into a PDF File. Scanning a letter document into a PDF digitizes your business’s important documents in a way that enables text searches.
The software technology that makes such searches possible is called optical character recognition (OCR). Some services or programs can scan your document, use OCR to convert the scanned image to readable text, and save the result as a PDF. However, these services and programs often cost money. With free resources, you can scan your documents and transform them into searchable PDFs. Google Drive and Google Docs Step 1 Scan your letter document and save the result as an image file. Step 2. Pdftotext(1) - Linux man page. Name pdftotext - Portable Document Format (PDF) to text converter (version 3.00) Synopsis pdftotext [options] [PDF-file [text-file]] Description Pdftotext converts Portable Document Format (PDF) files to plain text.
Pdftotext reads the PDF file, PDF-file, and writes a text file, text-file. Options -f number Specifies the first page to convert. -l number Specifies the last page to convert. Can OCR software reliably read values from a table. Ron Cemer's Blog. Several years back, I was working on an imaging project in Java which was going to require some Optical Character Recognition (OCR) functionality.

After an exhaustive search, I could find nothing to fit the bill. My requirements were: Must be written in JavaMust be freely redistributable, with or without source codeMust not be proprietaryMust be able to recognize the fonts of various printers, even if that means that it has to be trained for each new fontMust be reasonably fast I never found anything that met my requirements, so I set about developing something to fit the bill. What I ended up developing, is a generic, trainable OCR package that does a fairly decent job of decoding printed text, as long as it has been trained for the font(s) it is expected to recognize. How it Works This OCR engine is implemented as a Java library, along with a demo application which shows the library in action.
The Training Phase Training consists of the following steps: Capture2Text. Tesseract - first experiences. Tesseract is a good OCR machine, it works better than any other open source system I have tried so far.

The code is fragile and buggy - trivial problems will crash tesseract. Five particular crashes are fixed by the five patches patch1, patch2, patch3, patch5, patch6, but these were just the problems encountered in the very first attempt to use Tesseract. The source has a design mistake, in that there is no type unichar for Unicode character. Instead, Unicode strings are carried around in UTF-8, together with an array that gives the lengths of the substrings that represent the individual Unicode characters. This causes code and dictionary bloat, slows down the program, and causes worse OCR performance. The software has a design mistake in that it talks about "language" where no language is involved.
The dictionary files involve nonportable binary data. Info Some web resources: Google Tesseract. Download tesseract-2.01.tar.gz and the small patch tesseract-2.01.patch1.tar.gz, and compile.