
Ansible role reusability, private git repos, and dependencies. About this post Writing reusable roles for Ansible is not an easy task but one that’s worth doing.

This post should walk you through the basics of writing reusable roles with dependencies backed by public and private git repositories. Why do it? One of the great advantages of Ansible is that it is easy to learn and straightforward to use. That means you are able to achieve a specific task in a relatively short period of time and without complete knowledge of the full capabilities of the system. Sounds good, doesn’t it? To quote the documentation about roles: “You absolutely should be using roles. One of the reasons why roles are great is that they are REUSABLE. Having well written and flexible roles has its advantages: Smaller roles with dependencies. What you should keep in mind Creating reusable Ansible roles by following best practices is not as easy as it sounds but it’s definitely worth taking that challenge.
Making everything in the role configurable (overdoing it). Ansible role reusability, private git repos, and dependencies. Graham Brooks - Zero Down-time - relational databases. Continuous Deployment is the act of automatically deploying an application every time the build is successful.

I am currently working with a development team that is working towards continuous deployment as part of their continuous delivery adoption plans. The system involves several internal web services which seemed like a good place to start working on not only automating the deployments but maintaining a very high degree of up-time during those deployments. Automating deployments involves both development and techops groups so I thought I would search for some worked examples that would help illustrate the techniques and steps required. I found several blogs and articles talking about different approaches but no worked examples. This article steps through the process but also includes a complete worked example.
For the impatient the source code and rake script for this example can be found at. Blue-Turquoise-Green Deployment. In this post I’m putting a name to something I’ve found myself doing in order to deliver zero-downtime deployments without any loss of database consistency.
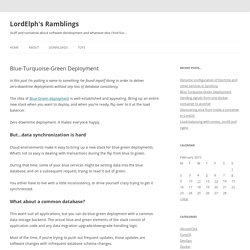
The idea of Blue-Green deployment is well-established and appealing. Bring up an entire new stack when you want to deploy, and when you’re ready, flip over to it at the load balancer. Zero downtime deployment. It makes everyone happy. But…data synchronization is hard Cloud environments make it easy to bring up a new stack for blue-green deployments. During that time, some of your blue services might be writing data into the blue database, and on a subsequent request, trying to read it out of green. Blue-Green Deployment With a Single Database. A blue-green deployment is a way to have incremental updates to your production stack without downtime and without any complexity for properly handling rolling updates (including the rollback functionality) I don’t need to repeat this wonderful explanation or Martin Fowler’s original piece.

But I’ll extend on them. A blue-green deployment is one where there is an “active” and a “spare” set of servers. The active running the current version, and the spare being ready to run any newly deployed version. BlueGreenDeployment. Delivery tags: One of the goals that my colleagues and I urge on our clients is that of a completely automated deployment process.
Automating your deployment helps reduce the frictions and delays that crop up in between getting the software "done" and getting it to realize its value. Dave Farley and Jez Humble are finishing up a book on this topic - Continuous Delivery. It builds upon many of the ideas that are commonly associated with Continuous Integration, driving more towards this ability to rapidly put software into production and get it doing something. One of the challenges with automating deployment is the cut-over itself, taking software from the final stage of testing to live production. Blue-green deployment also gives you a rapid way to rollback - if anything goes wrong you switch the router back to your blue environment.
The two environments need to be different but as identical as possible. Acknowledgements Illustration by Ketan Padegaonkar. Continuous Delivery: Anatomy of the Deployment Pipeline. The deployment pipeline is the key pattern that enables continuous delivery.
A deployment pipeline implementation provides visibility into the production readiness of your applications by giving feedback on every change to your system. It also enables team members to self-service deployments into their environments. Learn how to create and manage a deployment pipeline, and how to use the crucial information it provides on the bottlenecks in your software delivery process so you can work to continuously improve it. This chapter is from the book Rundeck - ordonnanceur centralisé opensource - vient de sortir sa v2.0. Rundeck est un ordonnanceur centralisé sous licence libre (Apache v2.0) et ils viennent de sortir (1er février 2014) une nouvelle version majeure qui est la 2.0.

La toute dernière version est d’ailleurs la 2.0.1 qui est sortie le 12 février pour corriger quelques bugs. On entends souvent parler d’orchestration centralisée, Rundeck est à ranger dans cette catégorie. Rundeck dispose d’une interface permettant de gérer les différents jobs à exécuter sur les différents serveurs, mais fournit également des outils en ligne de commande et une API Web Voici la liste de ses principales fonctionnalités : Voici la liste des principales nouveautés : Voici un screenshot de la nouvelle interface : Liens utiles : Site officiel de Rundeck Page Github de Rundeck. Continuous Delivery Software. CruiseControl Home.