
Pdf/1102.3537.pdf. Mining of Massive Datasets. The book has a new Web site www.mmds.org.

This page will no longer be maintained. Your browser should be automatically redirected to the new site in 10 seconds. The book has now been published by Cambridge University Press. The publisher is offering a 20% discount to anyone who buys the hardcopy Here. By agreement with the publisher, you can still download it free from this page. --- Jure Leskovec, Anand Rajaraman (@anand_raj), and Jeff Ullman Download Version 2.1 The following is the second edition of the book, which we expect to be published soon. There is a revised Chapter 2 that treats map-reduce programming in a manner closer to how it is used in practice, rather than how it was described in the original paper.
Version 2.1 adds Section 10.5 on finding overlapping communities in social graphs. Download the Latest Book (511 pages, approximately 3MB) Download chapters of the book: Download Version 1.0 Download the Book as Published (340 pages, approximately 2MB) Gradiance Support. Www.stanford.edu/class/cs345a/slides/04-highdim.pdf. C - How to understand Locality Sensitive Hashing. Locality-Sensitive Hashing. Hal.inria.fr/docs/00/56/71/91/PDF/paper.pdf. Set Similarity and Min Hash - Taming Uncertainty. Given two sets S1, S2, find similarity(S1, S2) - based not hamming distance (not Euclidean).
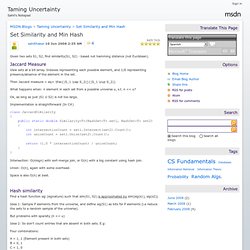
Jaccard Measure View sets at a bit-array. Indexes representing each possible element, and 1/0 representing presence/absence of the element in the set. Then Jaccard measure = What happens when: n element in each set from a possible universe u, s.t. n << u? Ok, as long as just |S1 U S2| is not too large. Implementation is straightforward (In C#) class JaccardSimilarity { public static double Similarity<T>(HashSet<T> set1, HashSet<T> set2) { int intersectionCount = set1.Intersect(set2).Count(); int unionCount = set1.Union(set2).Count(); return (1.0 * intersectionCount) / unionCount; } } Intersection: O(nlogn) with sort-merge join, or O(n) with a big constant using hash join. Union: O(n), again with some overhead. C# - Using MinHash to find similiarities between 2 images. W-shingling. The document, "a rose is a rose is a rose" can be tokenized as follows: (a,rose,is,a,rose,is,a,rose) The set of all contiguous sequences of 4 tokens (N-grams, here: 4-grams) is { (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose) } = { (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is) } Resemblance[edit] where |A| is the size of set A.
See also[edit] References[edit] (Manber 1993) Finding Similar Files in a Large File System. External links[edit] An implementation of the shingling algorithm in C++ Jeffrey D. Ullman. Jeff Ullman is the Stanford W.

Ascherman Professor of Computer Science (Emeritus). His interests include database theory, database integration, data mining, and education using the information infrastructure. What's New | Polemics | Books | Biographical Information What's New Workshop on Algorithms for MapReduce and Beyond I have gotten involved in a Workshop "Algorithms for MapReduce and Beyond" that will be held March 28, 2014 in Athens, in conjunction with EDBT/ICDT.
New Polemic Experiments as Research Validation -- Have We Gone too Far?. Follow Me on Google+ I refuse to get involved with Facebook, or Twitter, or LinkedIn, or any of the old social-network sites, but I have started to post observations and reports of my trips and such on Google+. Map-Reduce Algorithms Along with a number of colleagues, I have been looking at the question of algorithm design for Hadoop (MapReduce). Gradiance News Gradiance is a system for creating and administering class exercises. Polemics. Efficient large-scale sequence comparison by locality-sensitive hashing. Www.cs.gmu.edu/~hrangwal/files/SDM_MCLSH.pdf. Infolab.stanford.edu/~ullman/mmds/ch3a.pdf.