
LIBSVM FAQ. Feature selection. In machine learning and statistics, feature selection, also known as variable selection, attribute selection or variable subset selection, is the process of selecting a subset of relevant features for use in model construction.
The central assumption when using a feature selection technique is that the data contains many redundant or irrelevant features. Redundant features are those which provide no more information than the currently selected features, and irrelevant features provide no useful information in any context. Feature selection techniques are a subset of the more general field of feature extraction. Feature extraction creates new features from functions of the original features, whereas feature selection returns a subset of the features. Feature selection techniques are often used in domains where there are many features and comparatively few samples (or data points). Improved model interpretability,shorter training times,enhanced generalisation by reducing overfitting.
The. Weka 3 - Data Mining with Open Source Machine Learning Software in Java. Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization. Found only on the islands of New Zealand, the Weka is a flightless bird with an inquisitive nature. Q-Learning By Examples. By Kardi Teknomo Share this: Google+ In this tutorial, you will discover step by step how an agent learns through training without teacher in unknown environment.

Reinforcement learning is training paradigm for agents in which we have example of problems but we do not have the immediate exact answer. Sample code for Q-learning. Www.acm.uiuc.edu/sigart/docs/QLearning.pdf. Reinforcement Learning - Algorithms. The parameters used in the Q-value update process are: - the learning rate, set between 0 and 1.

Setting it to 0 means that the Q-values are never updated, hence nothing is learned. Setting a high value such as 0.9 means that learning can occur quickly. - discount factor, also set between 0 and 1. This models the fact that future rewards are worth less than immediate rewards. . - the maximum reward that is attainable in the state following the current one. i.e the reward for taking the optimal action thereafter. This procedural approach can be translated into plain english steps as follows: Initialize the Q-values table, Q(s, a). Sarsa. Introduction to Reinforcement Learning. Xin Chen.

University of Hawaii. Fall 2006. DBSCAN.M - dmfa07 - MATLAB code for dbscan - Data Mining projects for the class CIS4930 Fall 2007, Data Mining with Sanjay Ranka. AGHC.m - Classical data mining algorithm matlab c - Source Codes Reader - HackChina. K-Means Clustering Tutorial: Matlab Code. Kmeans: Matlab Code. Contents.m - Classical data mining algorithm matlab c - Source Codes Reader - HackChina. K_means.m - Classical data mining algorithm matlab c - Source Codes Reader - HackChina. Sponser links:
Backpropagation. The project describes teaching process of multi-layer neural network employing backpropagation algorithm.
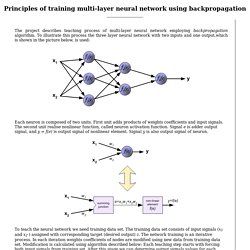
To illustrate this process the three layer neural network with two inputs and one output,which is shown in the picture below, is used: Each neuron is composed of two units. First unit adds products of weights coefficients and input signals. The second unit realise nonlinear function, called neuron activation function. Signal e is adder output signal, and y = f(e) is output signal of nonlinear element. FLD - Fisher Linear Discriminant. FLD - Fisher Linear Discriminant Let us assume we have sets , these represent classes, each containing elements ( ).

Is to dimensionality , where we believe the classification will be more straightforward, maybe possible using linear classifier. Fisher's Linear Discriminant is trying to maximize the ratio of scatter between classes to the scatter within classes. Two Classes Classification First let us illustrate this problem in two classes problem. That the projection on vector gives us a chance to find some threshold suitable for distinguishing whether a potential test sample belongs to class or.
Research.cs.tamu.edu/prism/lectures/pr/pr_l10.pdf. Www.physics.ohio-state.edu/~gan/teaching/spring04/Chapter5.pdf. CS 229: Machine Learning. CS340 Winter 2010. Stochastic Gradient Descent. (1 votes, average: 3.00 out of 5) Loading ...
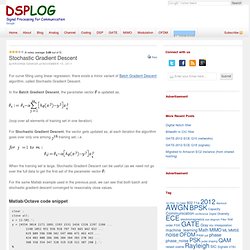
For curve fitting using linear regression, there exists a minor variant of Batch Gradient Descent algorithm, called Stochastic Gradient Descent. In the Batch Gradient Descent, the parameter vector is updated as, (loop over all elements of training set in one iteration) For Stochastic Gradient Descent, the vector gets updated as, at each iteration the algorithm goes over only one among. N'est pas accessible. Machine Learning 10-701/15-781. Batch Gradient Descent. I happened to stumble on Prof.
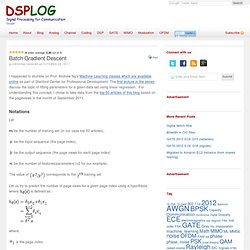
Andrew Ng’s Machine Learning classes which are available online as part of Stanford Center for Professional Development. The first lecture in the series discuss the topic of fitting parameters for a given data set using linear regression. For understanding this concept, I chose to take data from the top 50 articles of this blog based on the pageviews in the month of September 2011. Notations Let be the number of training set (in our case top 50 articles), be the input sequence (the page index), be the output sequence (the page views for each page index) be the number of features/parameters (=2 for our example).
The value of corresponds to the training set Let us try to predict the number of page views for a given page index using a hypothesis, where. Decision Tree. ID3 Decision Trees in Java. ID3 Decision Trees in Java In a previous post, I explored how one might apply decision trees to solve a complex problem.
This post will explore the code necessary to implement that decision tree. If you would like a full copy of the source code, it is available here in zip format. Entropy.java – In Entropy.java, we are concerned with calculating the amount of entropy, or the amount of uncertainty or randomness with a particular variable. For example, consider a classifier with two classes, YES and NO.