
Machine Learning Crash Course Google Developers. The Places API lets you search for place information using a variety of categories, including establishments, prominent points of interest, and geographic locations.
You can search for places either by proximity or a text string. A Place Search returns a list of places along with summary information about each place; additional information is available via a Place Details query. Find Place requests A Find Place request takes a text input and returns a place. The input can be any kind of Places text data, such as a name, address, or phone number. A Find Place request is an HTTP URL of the following form: where output may be either of the following values: json (recommended) indicates output in JavaScript Object Notation (JSON) xml indicates output as XML Certain parameters are required to initiate a Find Place request. Required parameters key — Your application's API key. Optional parameters Fields Use the fields parameter to specify a comma-separated list of place data types to return. Basic. Google Developers. Introduction Using Maps URLs, you can build a universal, cross-platform URL to launch Google Maps and perform searches, get directions and navigation, and display map views and panoramic images.
The URL syntax is the same regardless of the platform in use.
Duplicate Content - Google SERP. Tools / Apps / Software. Web Scraping Without Getting Blocked by Anti Scraping Tools. Web scraping is a task that has to be performed responsibly so that it does not have a detrimental effect on the sites being scraped. Web Crawlers can retrieve data much quicker, in greater depth than humans, so bad scraping practices can have some impact on the performance of the site. If a crawler performs multiple requests per second and downloads large files, an under-powered server would have a hard time keeping up with requests from multiple crawlers. Since web crawlers, scrapers or spiders (words used interchangeably) don’t really drive human website traffic and seemingly affect the performance of the site, some site administrators do not like spiders and try to block their access. Most websites may not have anti-scraping mechanisms since it would affect the user experience, but some sites do block scraping because they do not believe in open data access.
In this article, we will talk about how to scrape websites without getting blocked by the anti-scraping or bot detection tools. Best Social Media Aggregator for Embed and Display — 2020. Exploring and building up all the felicitous content from various social media platforms into one unified form is what a social media aggregator tool does.
It collects and curates all social media feeds through a specific hashtag or handles and displays those social feeds on digital signage or live screen during an event, conference, trade shows, fests, etc. You can also embed these live social feeds on your websites. So, without wasting much time, let’s find out how to choose the best social media aggregator for websites or events. Thought-process with continuous-aggregate-of-change: new release. Books and education websites treat knowledge as “matter-of-fact”.
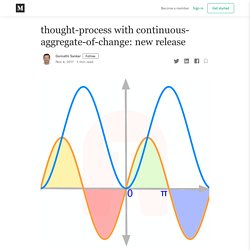
In comparison to those, nubtrek provides a thought process to discover the knowledge. In this post, the two are is explained for integral calculus. Introducing Integral as anti-derivative : Reference Khan Academy Definite integral as area of curve : Reference Khan Academy In these the knowledge is presented as “matter-of-fact” for students to learn. Puppeteer/puppeteer: Headless Chrome Node.js API. Getting Started with Headless Chrome Headless Chrome is shipping in Chrome 59.
It's a way to run the Chrome browser in a headless environment. Essentially, running Chrome without chrome! It brings all modern web platform features provided by Chromium and the Blink rendering engine to the command line. Download profile, hashtag data (jaroslavhejlek/instagram-scraper) · Apify. Features Since Instagram has removed the option to load public data through its API, this actor should help replace this functionality.

It allows you to scrape posts from a user's profile page, hashtag page or place. A Fast and Powerful Scraping and Web Crawling Framework. SeleniumHQ Browser Automation. Fast, flexible, and lean implementation of core jQuery designed specifically for the server. Beautiful Soup: We called him Tortoise because he taught us. [ Download | Documentation | Hall of Fame | For enterprise | Source | Changelog | Discussion group | Zine ] You didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help. Since 2004, it's been saving programmers hours or days of work on quick-turnaround screen scraping projects.
Onevcat/Kingfisher: A lightweight, pure-Swift library for downloading and caching images from the web. A Question & Answer platform where users can find answers to popular search queries. Welcome to Flask — Flask Documentation (1.1.x) A Hybrid Recommender with Yelp Challenge Data — Part I. This is the first part of the Yelper_Helper capstone project blog post.
Please find the second part here. 1. Intro Nowadays every company and individual can use a recommender system -- not just customers buying things on Amazon, watching movies on Netflix, or looking for food nearby on Yelp. In fact, one fundamental driver of data science’s skyrocketing popularity is the overwhelming amount of information available for anyone trying to make a good decision. This is the capstone project sitting at the end of our 12 week journey in the data science bootcamp.