
Emilwallner/Screenshot-to-code-in-Keras: A neural network that transforms a screenshot into a static website. Turning Design Mockups Into Code With Deep Learning - FloydHub Blog. Within three years deep learning will change front-end development.
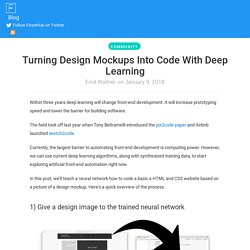
It will increase prototyping speed and lower the barrier for building software. The field took off last year when Tony Beltramelli introduced the pix2code paper and Airbnb launched sketch2code. Currently, the largest barrier to automating front-end development is computing power. However, we can use current deep learning algorithms, along with synthesized training data, to start exploring artificial front-end automation right now. In this post, we’ll teach a neural network how to code a basic a HTML and CSS website based on a picture of a design mockup. 1) Give a design image to the trained neural network 2) The neural network converts the image into HTML markup 3) Rendered output We’ll build the neural network in three iterations.
In the first version, we’ll make a bare minimum version to get a hang of the moving parts. All the code is prepared on Github and FloydHub in Jupyter notebooks. Let’s recap our goal. Neural Networks: You’ve Got It So Easy. Neural networks are all the rage right now with increasing numbers of hackers, students, researchers, and businesses getting involved.

The last resurgence was in the 80s and 90s, when there was little or no World Wide Web and few neural network tools. The current resurgence started around 2006. TensorFlow — an Open Source Software Library for Machine Intelligence. Multistyle Pastiche Generator. Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur have extended image style transfer by creating a single network which performs more than one stylization of an image.
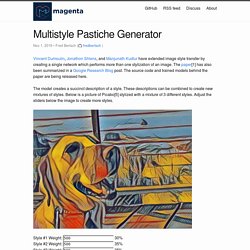
The paper[1] has also been summarized in a Google Research Blog post. The source code and trained models behind the paper are being released here. The model creates a succinct description of a style. Research Blog: Introducing the Open Images Dataset. Posted by Ivan Krasin and Tom Duerig, Software Engineers In the last few years, advances in machine learning have enabled Computer Vision to progress rapidly, allowing for systems that can automatically caption images to apps that can create natural language replies in response to shared photos.
Much of this progress can be attributed to publicly available image datasets, such as ImageNet and COCO for supervised learning, and YFCC100M for unsupervised learning. Today, we introduce Open Images, a dataset consisting of ~9 million URLs to images that have been annotated with labels spanning over 6000 categories. We tried to make the dataset as practical as possible: the labels cover more real-life entities than the 1000 ImageNet classes, there are enough images to train a deep neural network from scratch and the images are listed as having a Creative Commons Attribution license*. CILVR Lab @ NYU. OverFeat OverFeat is an image recognizer and feature extractor built around a convolutional network.
The OverFeat convolutional net was trained on the ImageNet 1K dataset. It participated in the ImangeNet Large Scale Recognition Challenge 2013 under the name “OverFeat NYU”. I'm Ken Stanley, artificial intelligence professor who breeds artificial brains that control robots and video game agents, and inventor of the NEAT algorithm – AMA! : IAmA. CORPORA: 1.9 billion - 45 million words each: free online access. Large Network Dataset Collection. Computational Investigation of Translationese. Project description Objective To use insights from Translation Studies for improving the quality of machine translation; and to use computational methodology for corroborating hypotheses of Translation Studies.

Researchers In Haifa, Noam Ordan, Gennadi Lembersky, Vered Volansky, Ella Rabinovich and Shuly Wintner. This project is joint with a team at Bar Ilan University, headed by Moshe Koppel. Status Ongoing Funding. Alternative Interfaces. I have every publicly available Reddit comment for research. ~ 1.7 billion comments @ 250 GB compressed. Any interest in this? : datasets.
MassMine: Your Access To Big Data. Java API for WordNet Searching (JAWS) From within the application you started you can use JAWS by first obtaining an instance of WordNetDatabase with code like the following, which assumes that you've performed an import of the classes in the edu.smu.tspell.wordnet package: WordNetDatabase database = WordNetDatabase.getFileInstance(); Once you've done so, you can begin to retrieve synsets from the database as shown in the example below.

This code retrieves all noun synsets for "fly" and loops through each one printing its first word form, its description, and the number of hyponyms associated with that noun synset: KOPI - Wikipedia as text download page. Datasets for Data Mining and Data Science. See also Data repositories AssetMacro, historical data of Macroeconomic Indicators and Market Data.
Awesome Public Datasets on github, curated by caesar0301. Full Reddit Submission Corpus now available (2006 thru August 2015) : datasets. Data: Querying, Analyzing and Downloading: The GDELT Project. AWS Public Data Sets. High resolution climate data to help assess the impacts of climate change primarily on agriculture.
Yahoo Labs. Summary of Data Sets by Data Type. Caesar0301/awesome-public-datasets. Now Available on Azure ML – Criteo's 1TB Click Prediction Dataset - Machine Learning. This post is by Misha Bilenko, Principal Researcher in Microsoft Azure Machine Learning.

Measurement is the bedrock of all science and engineering. Progress in the field of machine learning has traditionally been measured against well-known benchmarks such as the many datasets available in the UCI-ML repository, in the KDDCup and Kaggle contests and on ImageNet. New Dataset release. March 31st, 2015 New Dataset Criteo is pleased to announce the release of a new dataset which is an extended version of our Kaggle click prediction dataset. Apache Spark User List - Dataset announcement. This post has NOT been accepted by the mailing list yet. Dear Spark users, I would like to draw your attention to a dataset that we recently released, which is as of now the largest machine learning dataset ever released; see the following blog announcements: - - The characteristics of this dataset are: - 1 TB of data - binary classification - 13 integer features - 26 categorical features, some of them taking millions of values.