
Ag-ds-bubble/swtloc: Python package for Stroke Width Transform - Localizing the Text in a Natural Image. How to Train and Deploy Custom Models with Amazon SageMaker - Part 1. Training a TensorFlow image classifier on AWS Amazon SageMaker is an amazing service that allows you to build complete, end-to-end machine learning pipelines, from model training to production deployment.
It comes with a huge set of built-in models that you can use straight away, but it also allows you to train your own custom models via Docker images, giving you total control over the fun part of the process (i.e., model architecture and training logic) and yet abstracting away the boring part (model serving, instance creation, load balancing, scaling, etc).
In this tutorial series, I’m going to show you how you can use Amazon SageMaker and Docker to train and save a deep learning model, and then deploy your trained model as an inference endpoint. You will need AWS CLI and Docker installed on your machine (optional: install the Kaggle CLI to download the dataset). For this project, you will need to have access to the following AWS services: Step 1: Upload the dataset to AWS S3 aws s3 mb. Transformers from scratch. I will assume a basic understanding of neural networks and backpropagation.

If you’d like to brush up, this lecture will give you the basics of neural networks and this one will explain how these principles are applied in modern deep learning systems. A working knowledge of Pytorch is required to understand the programming examples, but these can also be safely skipped. Self-attention The fundamental operation of any transformer architecture is the self-attention operation. Self-attention is a sequence-to-sequence operation: a sequence of vectors goes in, and a sequence of vectors comes out. To produce output vector \y_\rc{i}, the self attention operation simply takes a weighted average over all the input vectors \y_\rc{i} = \sum_{\gc{j}} w_{\rc{i}\gc{j}} \x_\gc{j} \p Where \gc{j} indexes over the whole sequence and the weights sum to one over all \gc{j}.
Comment monter son propre VPN sur un serveur. Parce que le fonctionnement d’un VPN repose sur des serveurs, des protocoles réseau et des technologies de sécurité complexes, monter soi-même son propre VPN peut sembler hors de portée du simple mortel.
Est-ce vraiment le cas ? On a tenté de monter nous-mêmes notre propre VPN sur un serveur. Est-ce si difficile que cela de monter son propre service de VPN ? Et est-ce que l’opération est rentable par rapport à un service de VPN « prêt à l’emploi », comme ExpressVPN ? Fr.player. Gaussian Mixture Model. If the number of components K is known, expectation maximization is the technique most commonly used to estimate the mixture model's parameters.
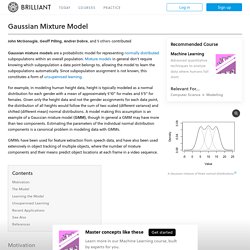
In frequentist probability theory, models are typically learned by using maximum likelihood estimation techniques, which seek to maximize the probability, or likelihood, of the observed data given the model parameters. Unfortunately, finding the maximum likelihood solution for mixture models by differentiating the log likelihood and solving for 0 is usually analytically impossible.
Expectation maximization (EM) is a numerical technique for maximum likelihood estimation, and is usually used when closed form expressions for updating the model parameters can be calculated (which will be shown below). Expectation maximization is an iterative algorithm and has the convenient property that the maximum likelihood of the data strictly increases with each subsequent iteration, meaning it is guaranteed to approach a local maximum or saddle point.
Quickstart — MLflow 1.8.0 documentation. Installing MLflow You install MLflow by running: Python R install.packages("mlflow")mlflow::install_mlflow() Note MLflow works on MacOS.
At this point we recommend you follow the tutorial for a walk-through on how you can leverage MLflow in your daily workflow. Downloading the Quickstart Download the quickstart code by cloning MLflow via git clone and cd into the examples subdirectory of the repository. We avoid running directly from our clone of MLflow as doing so would cause the tutorial to use MLflow from source, rather than your PyPi installation of MLflow.
Using the Tracking API The MLflow Tracking API lets you log metrics and artifacts (files) from your data science code and see a history of your runs. Isolation Forest. Isolation forest: Cet algorithme non supervisé de machine learning permet de détecter des anomalies dans un jeu de données.
Il isole les données atypiques, autrement dit celles qui sont trop différentes de la plupart des autres données. Cet algorithme calcule, pour chaque donnée du jeu, un score d’anomalie, c’est à dire une mesure qui reflète à quel point la donnée en question est atypique. Afin de calculer ce score, l’algorithme isole la donnée en question de manière récursive : il choisit un descripteur et un “seuil de coupure” au hasard, puis il évalue si cela permet d’isoler la donnée en question ; si tel est le cas, l’algorithme s’arrête, sinon il choisit un autre descripteur et un autre point de coupure au hasard, et ainsi de suite jusqu’à ce que la donnée soit isolée du reste. Comme pour les forêts aléatoires, il est possible d’exécuter cette démarche indépendamment en utilisant plusieurs arbres, afin de combiner leurs résultats pour gagner en performance.
Browse the State-of-the-Art in Machine Learning.
Cabinet de curiosité. Oversampling. Critères de scissions des arbres.