
新标签页. Columbia University. Biography Yan Wang is a PhD candidate in DVMM Lab, Columbia University, supervised by Prof.
Shih-Fu Chang. He received his bachelor's degree in Computer Science from University of Science and Technology of China, Hefei, China, in 2010. IEEE T-SMC:B Special Issue 2012 : Computer Vision for RGB-D Sensors: Kinect and Its Applications (Special issue on IEEE Transactions on Systems, Man and Cybernetics - Part B: Cybernectics) Depth cameras have been exploited in computer vision for several years, but the high price and the poor quality of such devices have limited their applicability.

With the invention of the low-cost Microsoft Kinect sensor, high-resolution depth and visual (RGB) sensing has become available for widespread use as an off-the-shelf technology. The complementary nature of the depth and visual (RGB) information in the Kinect sensor opens up new opportunities to solve fundamental problems in computer vision, including object and activity recognition, people tracking, 3D mapping and localization, etc.
Professor Heng Tao Shen - UQ reSEARCHers (Biography) Vision and Autonomous Systems Center. Ms research kinect. Kinect身份识别:技术与经验_微软亚洲研究院. 特别声明:本文是由文章Kinect Identity: Technology and Experience翻译而成,作者:Tommer Leyvand, Casey Meekhof, Yi-Chen Wei, Jian Sun, Baining Guo。
原文发表于期刊《IEEE计算机学会》(IEEE Computer Society)。 Kinect身份识别是微软Xbox 360的Kinect体感设备的重要组成部分之一,它将多种技术和精心设计的用户交互整合在一起,旨在实现玩家身份识别与跟踪的目标。 作者:微软公司Tommer Leyvand、Casey Meekhof、危夷晨 、孙剑和郭百宁 很多年来,不用控制器的沉浸式游戏(controller-less immersion)一直是游戏设计师和开发人员心目中的至高境界。 其中主要的挑战之一就是如何无缝地跟踪和成功地识别游戏中某个人的身份,以保证用户界面的顺畅和自然。 到目前为止,还没有完美的解决方案。 Yichen Wei. Efficient Optimziation of Photo Collage Yichen Wei, Yasuyuki Matsushita and Yingzhen Yang Technical Report, Microsoft Research, MSR-TR-2009-59, May, 2009.
(pdf 2M) Go to project page. Projects: Attribute and Simile Classifiers for Face Verification. Projects: FaceTracer: A Search Engine for Large Collections of Images with Faces. The ability of current search engines to find images based on facial appearance is limited to images with text annotations.

Yet, there are many problems with annotation-based search of images: the manual labeling of images is time-consuming; the annotations are often incorrect or misleading, as they may refer to other content on a webpage; and finally, the vast majority of images are simply not annotated. We have created the first face search engine, allowing users to search through large collections of images which have been automatically labeled based on the appearance of the faces within them. Our system lets users search on the basis of a variety of facial attributes using natural language queries such as, "men with mustaches," or "young blonde women," or even, "indoor photos of smiling children. " Poselets. Abstract We address the classic problems of detection and segmentation using a part based detector that operates on a novel part, which we refer to as a poselet.

Poselets are tightly clustered in both appearance space (and thus are easy to detect) as well as in configuration space (and thus are helpful for localization and segmentation). We demonstrate poselets are effective for detection, pose extraction, segmentation, action/pose estimation and attribute classification. Poselet construction requires extra annotations beyond the object bounds. Special Issue on Visual Understanding and Applications with RGB-D Cameras - Journal of Visual Communication and Image Representation. Rogerio Feris Website. Devi Parikh - Publications. Actively Selecting Annotations Among Objects and Attributes. Abstract We present an active learning approach to choose image annotation requests among both object category labels and the objects' attribute labels.

The goal is to solicit those labels that will best use human effort when training a multiclass object recognition model. In contrast to previous work in active visual category learning, our approach directly exploits the dependencies between human-nameable visual attributes and the objects they describe, shifting its requests in either label space accordingly. Behjat Siddiquie. Visual Geometry Group Home Page.
Overview Learning object categories has recently become a major focus of Computer Vision.
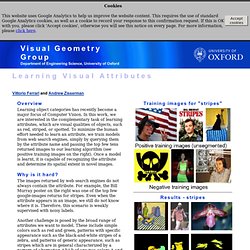
In this work, we are interested in the complementary task of learning attributes, which are visual qualities of objects, such as red, striped, or spotted. To minimize the human effort needed to learn an attribute, we train models from web search engines, simply by querying them by the attribute name and passing the top few tens returned images to our learning algorithm (see positive training images on the right). Once a model is learnt, it is capable of recognizing the attribute and determine its spatial extent in novel images. Why is it hard? The images returned by web search engines do not always contain the attribute. Another challenge is posed by the broad range of attributes we want to model.
Having learnt an attribute, when we are given a novel image, the challenge is to segment out the area covered by the attribute, rather than simply determining whether it is present or absent. 关于Attribute(s)和Pattern Recognition. 关于Attribute(s)和Pattern Recognition 发表于526 天前 ⁄ 科研 ⁄ 被围观 2210 次+ Attribute:属性。 这个词一直在Computer Vision领域以及Information Retrieval频频出现。 基本作用大体是这样的:咱们知道有对象的概念,那么对象就有自己的属性。 例如人这个对象,可以把投、躯干、四肢看做属性。 在对一个对象进行识别的时候,可以将几乎尽量多的属性集成起来做全局优化,因为存在集成的思想,考虑越全面,解决好效率问题,识别结果理论上会有所提高。 下面我大体简单的挑了几篇关于Attribute的论文,大部分在CV和IR领域。 R. ICCV 2011的一篇Oral: Relative Attributes. ICCV 2011的一篇Oral: Relative Attributes 发表于428 天前 ⁄ 科研 ⁄ 被围观 2673 次+ 今天看cv界的美女教授 Kristen Grauman 的页面时候,想看看最近又有什么新作出来,还真发现了一篇想法不错的文章【没想到后来竟然中了Best Paper】,我还没有细读,但是大体思想可以看看,拿出来大家一起看看读读,有啥想法或者启示。 Homepage of Bangpeng Yao. Kristen Grauman.
My research interests are in computer vision and machine learning.

In general, the goal of computer vision is to develop the algorithms and representations that will allow a computer to autonomously analyze visual information. Relative Attributes. Relative Attributes Marr Prize (Best Paper Award) Winner, ICCV 2011 Devi Parikh and Kristen Grauman (View this page's Romanian transation courtesy of azoft) (View this page's Slovakian translation courtesy of Sciologness Team) “Who in the rainbow can draw the line where the violet tint ends and the orange tint begins?

[paper] [data] [code] [demos] [slides] [talk (video)] [poster] Parts and Attributes Workshop.