
Netdb11-final12.pdf. Tools for building a real time analytics platform. Recently I did a bit of research on tools that are often mentioned in articles about ‘big data’ and real time analytics.

Through this article I hope to provide some insight in how some of those tools might be used together to build a real time analytics platform. The tools I used in this particular case are Storm and Apache Camel. When you’re interested in real time analytics the main challenge is (perhaps quite obviously) the real-time part. As the phrase implies, real time analytics is analyzing or acting upon things as they happen. You must have all the parts in play to be able to fully utilize the benefits of real time processing.
A good starting point for this is Storm. Spouts: source of streams of tuples. Spouts and bolts can be wired together. Storm topology Storm is distributed, as such a Storm cluster consists of two types of nodes: the master node and the worker nodes. The implementation of these components is quite straightforward. The word counter bolt: Running a Multi-Broker Apache Kafka 0.8 Cluster on a Single Node. In this article I describe how to install, configure and run a multi-broker Apache Kafka 0.8 (trunk) cluster on a single machine.

The final setup consists of one local ZooKeeper instance and three local Kafka brokers. We will test-drive the setup by sending messages to the cluster via a console producer and receive those messages via a console receiver. I will also describe how to build Kafka for Scala 2.9.2, which makes it much easier to integrate Kafka with other Scala-based frameworks and tools that require Scala 2.9 instead of Kafka’s default Scala 2.8. Update Mar 2014: I have released a Wirbelsturm, a Vagrant and Puppet based tool to perform 1-click local and remote deployments, with a focus on big data related infrastructure such as Apache Kafka and Apache Storm. The Log: What every software engineer should know about real-time data's unifying abstraction.
I joined LinkedIn about six years ago at a particularly interesting time.
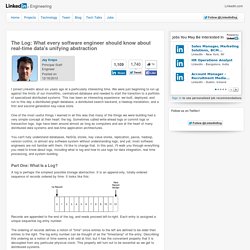
We were just beginning to run up against the limits of our monolithic, centralized database and needed to start the transition to a portfolio of specialized distributed systems. This has been an interesting experience: we built, deployed, and run to this day a distributed graph database, a distributed search backend, a Hadoop installation, and a first and second generation key-value store. One of the most useful things I learned in all this was that many of the things we were building had a very simple concept at their heart: the log. Sometimes called write-ahead logs or commit logs or transaction logs, logs have been around almost as long as computers and are at the heart of many distributed data systems and real-time application architectures. Part One: What Is a Log? A log is perhaps the simplest possible storage abstraction. Records are appended to the end of the log, and reads proceed left-to-right.
What's next. Jay Kreps, Apache Kafka Architect, Visits Cloudera. It was good to see Jay Kreps (@jaykreps), the LinkedIn engineer who is the tech lead for that company’s online data infrastructure, visit Cloudera Engineering yesterday to spread the good word about Apache Kafka.

Kafka, of course, was originally developed inside LinkedIn and entered the Apache Incubator in 2011. Today, it is being widely adopted as a pub/sub framework that works at massive scale (and which is commonly used to write to Apache Hadoop clusters, and even data warehouses). Perhaps the most interesting thing about Kafka is its treatment of the venerable commit log as its inspiring abstraction. As Jay puts it, the log is “the natural data structure for handling data flow between systems” — and he describes that approach is “pub/sub done right” (much more detail about this important concept here).
Jay kindly agreed to let us share his presentation with you, and here it is: Thanks Jay, we really appreciate your visit! Justin Kestelyn is Cloudera’s developer outreach director. Running a Multi-Broker Apache Kafka 0.8 Cluster on a Single Node.