HADOOP, HIVE, Map Reduce avec PHP : part 1
Lorsque l’on commence à débattre sur le «BIG DATA», on finit toujours par discuter du stockage. «Hadoop», de par son architecture et son fonctionnement, n’impose aucune contrainte technique sur le stockage de la donnée. Intégrant nativement le concept de Map & Reduce, «Hadoop» est un candidat sérieux pour les besoins de stockage massif et d’extraction qu’impose le «BIG DATA». Facebook a retenu «Hadoop» comme entrepôt de données pour ses calculs de statistiques marketing. Dans un précédent article consacré à «CASSANDRA», nous avions conclu «qu’une architecture permettant l’extraction, la manipulation et l’interprétation socio-économique de données massives, était composée de plusieurs maillons technologiques». «Hadoop» est l’un de ces chainons. Architecture technique Hadoop Le schéma ci-dessus décrit l’architecture technique d’une entreprise de e-commerce vendant des produits alimentaires pour animaux. Installation du framework HADOOP HIVE,PIG,ZOOKEEPER,AVRO,WHIRR,et bien d’autres encore.
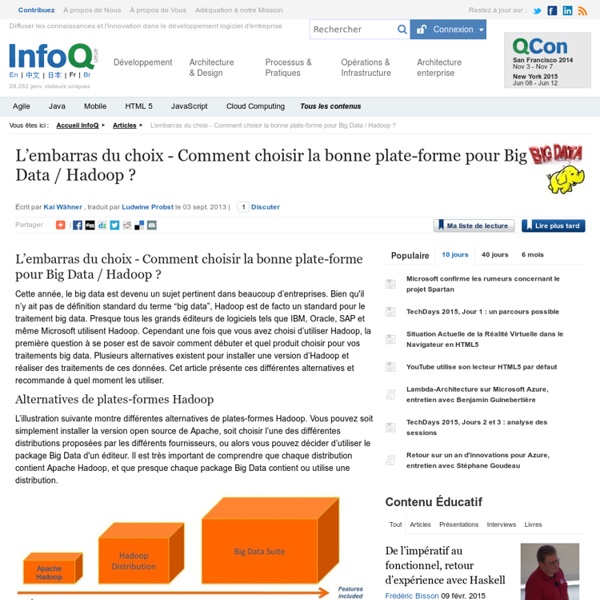
Big Data : La jungle des différentes distributions open source Hadoop
En 2004, Google a publié un article présentant son algorithme de calcul à grande échelle, MapReduce, ainsi que son système de fichier en cluster, GoogleFS. Rapidement (2005) une version open source voyait le jour sous l’impulsion de Yahoo. Aujourd’hui il est difficile de se retrouver dans la jungle d’Hadoop pour les raisons suivantes : Ce sont des technologies jeunes.Beaucoup de buzz et de communication de sociétés qui veulent prendre le train Big Data en marche.Des raccourcis sont souvent employés (non MapReduce ou un équivalent n’est pas suffisant pour parler d’Hadoop).Beaucoup d’acteurs différents (des mastodontes, des spécialistes du web, des start-up, …). Dans une distribution Hadoop on va retrouver les éléments suivants (ou leur équivalence) HDFS, MapReduce, ZooKeeper, HBase, Hive, HCatalog, Oozie, Pig, Sqoop, … Dans cet article on évoquera les trois distributions majeures que sont Cloudera, HortonWorks et MapR, toutes les trois se basant sur Apache Hadoop. Le cœur : Hadoop kernel MapR
#BigData : Un marché qui devrait atteindre 25 milliards de dollars d'ici fin 2016
Si le Big Data a de plus en plus le vent en poupe c’est pour une raison très simple : il va devenir vital pour quasiment toutes les entreprises dans tous les secteurs d’activité d’ici la fin de la décennie. La rédaction de Maddyness vous invite à décrypter les informations clés à connaître sur ce secteur qui devrait atteindre les 25 milliards de dollars de chiffre d’affaires d’ici la fin 2016, selon le cabinet IDC. Un potentiel énorme Si le terme de « Big Data » faisait encore peur il y a peu, il est véritablement en train de s’immiscer dans un grand nombre de DSI et plus généralement dans de nombreuses sociétés. Et le potentiel du secteur ne s’arrête pas là puisque même les poids lourds du numérique et/ou de l’informatique sont encore très loin d’avoir exploité la totalité des possibilités du Big Data. Pour en savoir plus sur l’avenir, les enjeux et les perspectives de la Data, RDV le 5 Février prochain à la Gaité Lyrique pour la 7ème édition de la Startup Keynote.
Réseau de neurones artificiels
Un article de Wikipédia, l'encyclopédie libre. Un réseau de neurones artificiels est un modèle de calcul dont la conception est très schématiquement inspirée du fonctionnement des neurones biologiques. Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type probabiliste, en particulier bayésien. Ils sont placés d’une part dans la famille des applications statistiques, qu’ils enrichissent avec un ensemble de paradigmes [1] permettant de créer des classifications rapides (réseaux de Kohonen en particulier), et d’autre part dans la famille des méthodes de l’intelligence artificielle auxquelles ils fournissent un mécanisme perceptif indépendant des idées propres de l'implémenteur, et fournissant des informations d'entrée au raisonnement logique formel. En modélisation des circuits biologiques, ils permettent de tester quelques hypothèses fonctionnelles issues de la neurophysiologie, ou encore les conséquences de ces hypothèses pour les comparer au réel.
Cinq étapes pour se préparer au traitement des big data
(crédit photo : D.R.) On parle beaucoup de « big bata » ces temps-ci. Un peu trop au goût de certains. Les acteurs IT et les experts qui s'y réfèrent les présentent néanmoins comme un actif stratégique clé des prochaines années. C'est sans doute le bon moment pour réfléchir aux orientations à prendre. Manipuler de larges volumes de données n'est pas une nouveauté pour les départements informatiques, mais derrière le battage fait sur la question, les big data diffèrent vraiment du datawarehouse, du datamining et de l'analyse décisionnelle qui les ont précédées, souligne Beth Stackpole, de Computerworld, dans un article publié cette semaine. Les données sont générées de plus en plus vite, la plupart étant désormais récupérées sous leur forme brute. Une fois cet état des lieux engagé, les équipes informatiques devraient entreprendre des projets très ciblés qui pourraient être utilisés pour montrer quels résultats on peut obtenir, plutôt que d'opter pour des projets en mode big-bang.
Le Big Data