
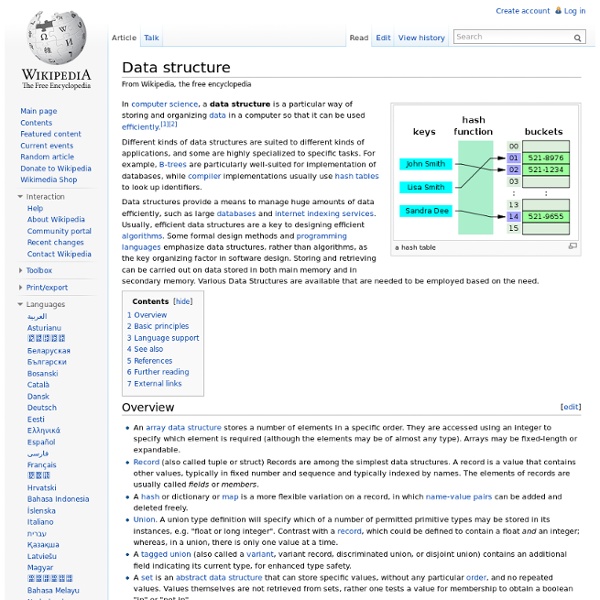
Category:Data structures In computer science, a data structure is a way of storing data in a computer so that it can be used efficiently. Often a carefully chosen data structure will allow a more efficient algorithm to be used. The choice of the data structure must begin from the choice of an abstract data structure. Subcategories This category has the following 13 subcategories, out of 13 total. Pages in category "Data structures" The following 43 pages are in this category, out of 43 total.
Term indexing Many operations in automatic theorem provers require search in huge collections of terms and clauses. Such operations typically fall into the following scheme. Given a collection of terms (clauses) and a query term (clause) , find in some/all terms related to according to a certain retrieval condition. . term is unifiable with term , i.e., there exists a substitution , such that = term is an instance of , i.e., there exists a substitution , such that = term is a generalisation of , i.e., there exists a substitution , such that = clause θ-subsumes clause , i.e., there exists a substitution , such that is a subset/submultiset of clause is θ-subsumed by , i.e., there exists a substitution , such that is a subset/submultiset of More often than not, we are actually interested in finding the appropriate substitutions explicitly, together with the retrieved terms , rather than just in establishing existence of such substitutions. , when the retrieval condition is tested on every term from
Monoque From Wikipedia, the free encyclopedia A monoque is a linear data structure which provides dynamic array semantics. A monoque is similar in structure to a deque but is limited to operations on one end. Hence the name, mono-que. The monoque consists of a size variable and a fixed-size block list of blocks with exponentially increasing sizes. Routing table Basics[edit] With hop-by-hop routing, each routing table lists, for all reachable destinations, the address of the next device along the path to that destination: the next hop. Assuming that the routing tables are consistent, the simple algorithm of relaying packets to their destination's next hop thus suffices to deliver data anywhere in a network. Hop-by-hop is the fundamental characteristic of the IP Internetwork Layer[1] and the OSI Network Layer. The primary function of a router is to forward a packet toward its destination network, which is the destination IP address of the packet. A routing table is a data file in RAM that is used to store route information about directly connected and remote networks. The network/exit-interface association can also represent the destination network address of the IP packet. A directly connected network is a network that is directly attached to one of the router interfaces. Difficulties with routing tables[edit] Contents of routing tables[edit]
Postings list From Wikipedia, the free encyclopedia The postings list is a data structure commonly used in information retrieval (IR) systems to store indexing information about a corpus. It is central to the design and efficiency of search engines and database management systems that need to retrieve information rapidly. At the bare minimum, a postings list is associated with a term from a document and records the places where that term appears. A postings list consists of posting elements, sometimes referred to as postings. A document identifier (DocID), which uniquely identifies a document in the corpus.Frequency information (Term Frequency), indicating how often the term appears within the document.Position information, indicating where in the text the term appears.Additional metadata may include fields such as document titles, headings, or other relevant document-specific information. Some variants of postings lists include:
Implicit data structure Categorization among data structures Definition[edit] An implicit data structure is one with constant O(1) space overhead (above the information-theoretic lower bound). Historically, Munro & Suwanda (1980) defined an implicit data structure (and algorithms acting on one) as one "in which structural information is implicit in the way data are stored, rather than explicit in pointers." They are somewhat vague in the definition, defining it most strictly as a single array, with only the size retained (a single number of overhead),[1] or more loosely as a data structure with constant overhead (O(1)).[2] This latter definition is today more standard, and the still-looser notion of a data structure with non-constant but small o(n) overhead is today known as a succinct data structure, as defined by Jacobson (1988); it was referred to as semi-implicit by Munro & Suwanda (1980).[3] Examples[edit] More sophisticated implicit data structures include the beap (bi-parental heap). History[edit]
Compressed data structure From Wikipedia, the free encyclopedia The term compressed data structure arises in the computer science subfields of algorithms, data structures, and theoretical computer science. It refers to a data structure whose operations are roughly as fast as those of a conventional data structure for the problem, but whose size can be substantially smaller. Important examples of compressed data structures include the compressed suffix array[1][2] and the FM-index,[3]both of which can represent an arbitrary text of characters T for pattern matching. An important related notion is that of a succinct data structure, which uses space roughly equal to the information-theoretic minimum, which is a worst-case notion of the space needed to represent the data.
List of data structures List of data structures From Wikipedia, the free encyclopedia Jump to: navigation, search This is a list of data structures. Contents [hide] Data types[edit] Primitive types[edit] Composite types[edit] (Sometimes also referred to as Plain old data structures.) Abstract data types[edit] Some properties of abstract data types: "Stable" means that input order is retained. Other structures such as "linked list" and "stack" cannot easily be defined this way because there are specific operations associated with them. Linear data structures[edit] Arrays[edit] Lists[edit] Trees[edit] Binary trees[edit] B-trees[edit] Heaps[edit] Trees[edit] In these data structures each tree node compares a bit slice of key values. Multiway trees[edit] Space-partitioning trees[edit] These are data structures used for space partitioning or binary space partitioning. Application-specific trees[edit] Hashes[edit] Graphs[edit] Other[edit] Retrieved from " Categories: Navigation menu Personal tools Namespaces
Comparison of data structures From Wikipedia, the free encyclopedia This is a comparison of the performance of notable data structures, as measured by the complexity of their logical operations. For a more comprehensive listing of data structures, see List of data structures. Lists[edit] peek: access the element at a given index.insert: insert a new element at a given index. Maps[edit] Maps store a collection of (key, value) pairs, such that each possible key appears at most once in the collection. Insert: add a new (key, value) pair to the collection, mapping the key to its new value. Unless otherwise noted, all data structures in this table require O(n) space. Integer keys[edit] Priority queues[edit] Priority queues are frequently implemented using heaps. Heaps[edit] heap property In addition to the operations of an abstract priority queue, the following table lists the complexity of two additional logical operations: Here are time complexities[7] of various heap data structures. Notes[edit] References[edit]
Oblivious data structure In computer science, an oblivious data structure is a data structure that gives no information about the sequence or pattern of the operations that have been applied except for the final result of the operations.[1] In most conditions, even if the data is encrypted, the access pattern can be achieved, and this pattern can leak some important information such as encryption keys. And in the outsourcing of cloud data, this leakage of access pattern is still very serious. We say a machine is oblivious if the sequence in which it accesses is equivalent for any two inputs with the same running time. Applications: Oblivious data structures[edit] Oblivious RAM[edit] Goldreich and Ostrovsky proposed this term on software protection. The memory access of oblivious RAM is probabilistic and the probabilistic distribution is independent of the input. steps of an oblivious . accesses in order to simulate t steps. Now we have the square-root algorithm to simulate the oblivious ram working. buckets.
Partition refinement In the design of algorithms, partition refinement is a technique for representing a partition of a set as a data structure that allows the partition to be refined by splitting its sets into a larger number of smaller sets. In that sense it is dual to the union-find data structure, which also maintains a partition into disjoint sets but in which the operations merge pairs of sets. In some applications of partition refinement, such as lexicographic breadth-first search, the data structure maintains as well an ordering on the sets in the partition. Partition refinement forms a key component of several efficient algorithms on graphs and finite automata, including DFA minimization, the Coffman–Graham algorithm for parallel scheduling, and lexicographic breadth-first search of graphs.[1][2][3] Data structure[edit] Such an algorithm may be implemented efficiently by maintaining data structures representing the following information:[4][5] Applications[edit] References[edit]