
Xerox PARC et la naissance de l’informatique contemporaine Au début des années 1970, les équipes du centre de recherche Xerox de Palo Alto élaborent les concepts et les outils qui vont façonner le visage de l’informatique actuelle. Vue de Xerox PARC.© Digibarn Computer Museum Dans ce contexte, la société Xerox décide qu’elle doit s’approprier les techniques informatiques pour assurer son avenir. Sa bonne santé financière lui permet alors d'engager deux actions complémentaires. Elle acquiert, en 1969, la société Scientific Data Systems (SDS), qui fabrique des ordinateurs de taille moyenne [2] et qui est bien placée sur le marché de l’informatique en temps réel. SDS devient XDS (Xerox Data Systems). Inventer le bureau du futur En 1970, Xerox disposait déjà d’un centre de recherche. La décision d’implanter le nouveau centre dans la Silicon Valley, loin du siège de Xerox, lui donnait une certaine indépendance, mais réduisait son poids et sa capacité de persuasion vis-à-vis de l’état-major de la société. Un environnement de travail révolutionnaire Notes
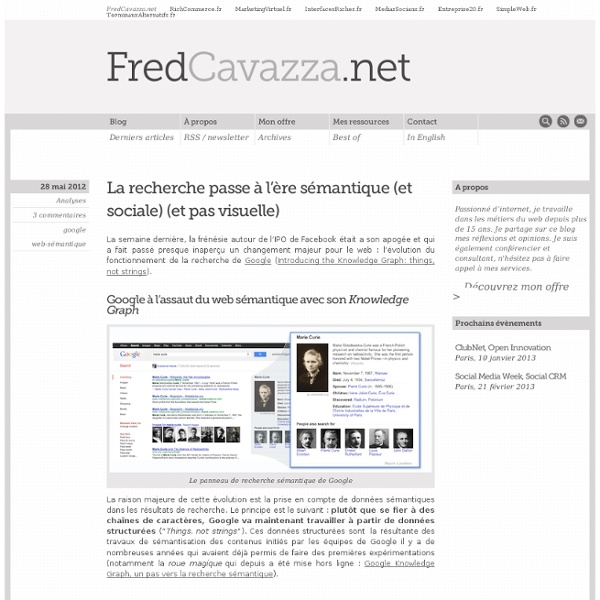
Knowledge Graph : Google officialise son moteur sémantique Les règles du jeu semblent distribuées depuis quelques jours entre les deux géants du search : Bing se lance dans le social tous azimuths, aidé par ses relations étroites avec Facebook et Twitter. Google, limité par le succès trop faible de son réseau Google+, se tourne - pour l'instant - vers d'autres voies d'innovation et intègre de plus en plus de sémantique dans ses résultats. Déjà en phase de test depuis plusieurs mois, ces fonctionnalités ont été annoncées officiellement par Google sous le nom de "Knowledge Graph". Cette nouvelle vision permet d'obtenir de très nombreux renseignements sur les "entités nommées" (noms de personnes, d'entreprises, de lieux, etc.) contenues dans la requête de l'internaute. Le "Knowledge Graph" sera présent dans les pages de résultats de Google, au fur et à mesure des semaines qui viennent, sous 3 formes différentes : - Désambigüisation de la requête demandée. - Propositions de liens pour en savoir plus sur des sujets proches de celui recherché :
tablettes Grenoble Ecole de Management fait vivre à des étudiants une expérience interdisciplinaire inédite : concevoir une application Smartphone avec des étudiants qu’ils ne connaissent pas et situés de l’autre côté de la planète. Explications de Barthélémy Chollet, enseignant-chercheur de cette école. Ils sont 600 étudiants de trois institutions, Grenoble Ecole de Management, Georgia Tech et George Mason University, à participer à cette expérimentation de grande ampleur réalisée sur deux ans. Les participants sont répartis en équipes réunissant trois disciplines : écologie, psychologie et management, avec pour cahier des charges la conception d’un concept d’application Smartphone en lien avec le développement durable. « Le cadre dans lequel nous réalisons ces travaux de recherche est très proche de celui des entreprises qui mènent des projets innovants » explique Barthélémy Chollet, enseignant – chercheur à Grenoble Ecole de Management. lu : 540 fois
Google Launches Knowledge Graph To Provide Answers, Not Just Links Hinted at for months, Google formally launched its “Knowledge Graph” today. The new technology is being used to provide popular facts about people, places and things alongside Google’s traditional results. It also allows Google to move toward a new way of searching not for pages that match query terms but for “entities” or concepts that the words describe. Knowledge Graph? “Graph” is a technical term used to describe how a set of objects are connected. Google has used a “link graph” to model how pages link to each other, in order to help determine which are popular and relevant for particular searches. Big Change, Subtle Appearance Earlier this year, the Wall Street Journal wrote about the coming change. Big change, but I don’t think it’ll be a shocking change to most Google users who will begin seeing it over the coming days on Google.com, if they’re searching in US English. Google will still look largely the same as it does now. Fact Surfing 3.5 Billion Facts About 500 Million Objects
pub:accompagnement [OSCAR] Formulaire d'abonnement en ligne. Le CRDP de l'académie de Lyon, en accord avec les préconisations de la mission TICE de l'académie de Lyon, propose un service en ligne, sur abonnement, d’accompagnement à l'usage du logiciel OSCAR. Ce service s'adresse en priorité aux établissements d'enseignements (1er degré, 2nd degré, supérieur) qui souhaitent optimiser l'accessibilité et la gestion des salles informatiques et du réseau pédagogique dont ils sont dotés. L'abonnement au Service d'accompagnement du logiciel OSCAR permet d'utiliser au mieux toutes les fonctionnalités du logiciel Outil Système Complet d'Assistance Réseau, OSCAR©. Tous les outils nécessaires à la gestion du parc informatique de l'établissement équipé du logiciel OSCAR (installation, réparation des postes, en local ou en réseau) sont disponibles sur le CD-Rom OSCAR fourni aux abonnés par le CRDP. Contenus Lisez les témoignages des administrateurs réseaux qui utilisent le service d'accompagnement.
Google : le 'Knowledge Graph' génère plus de requêtes... et de publicités Abondance > Actualités > Google : le 'Knowledge Graph' génère plus de requêtes... et de publicités Google a indiqué que depuis le lancement de l'application sémantique Knowledge Graph sur son moteur de recherche, le nombre de requêtes avait augmenté de façon importante. En effet, Amit Singhal, l'une des principales têtes pensantes de l'algorithme de Google, l'a indiqué dans le Wall Street Journal, information confirmée par le service de presse du moteur. Cela est logique dans le sens où le "Knowledge Graph" propose de nombreux liens concernant l'objet de la requête et de l'"entité nommée" détectée. D'ailleurs, cela pourrait clairement être à l'avantage de Google : l'internaute tape une requête sur la page d'accueil du moteur, obtient les résultats du Knowledge Graph, reclique sur les liens de recherche proposés, etc. Bref, autant de possibilité d'afficher des Adwords pour Google et autant de clics publicitaires potentiels ! Bref, qui est le gagant de cette nouveauté sémantique ?
Physique main levée: Méca gaz Welcome to YouTube! The location filter shows you popular videos from the selected country or region on lists like Most Viewed and in search results.To change your location filter, please use the links in the footer at the bottom of the page. Click "OK" to accept this setting, or click "Cancel" to set your location filter to "Worldwide". The location filter shows you popular videos from the selected country or region on lists like Most Viewed and in search results. Loading... 1 0:43 L'eau est arrêtée par le papier by Unisciel 8,541 views 2 1:09 Faire monter de l'eau avec une bougie by Unisciel 1,668 views 3 0:57 Faire imploser une canette by Unisciel 93,942 views 4 1:46 Un ballon est moins lourd lorsqu'il est gonflé by Unisciel 1,553 views 5 1:04 Eteindre une bougie avec du dioxyde de carbone by Unisciel 1,146 views 6 1:03 Le polystyrène rebelle by Unisciel 469 views 7 1:48 L'air ce n'est pas rien by Unisciel 942 views 8 1:33 L'abreuvoir à oiseaux by Unisciel 4,389 views 21 0:45 Vive le vent !
things, not strings Cross-posted on the Inside Search Blog Search is a lot about discovery—the basic human need to learn and broaden your horizons. But searching still requires a lot of hard work by you, the user. So today I’m really excited to launch the Knowledge Graph, which will help you discover new information quickly and easily. Take a query like [taj mahal]. But we all know that [taj mahal] has a much richer meaning. The Knowledge Graph enables you to search for things, people or places that Google knows about—landmarks, celebrities, cities, sports teams, buildings, geographical features, movies, celestial objects, works of art and more—and instantly get information that’s relevant to your query. Google’s Knowledge Graph isn’t just rooted in public sources such as Freebase, Wikipedia and the CIA World Factbook. The Knowledge Graph enhances Google Search in three main ways to start: 1. 2. How do we know which facts are most likely to be needed for each item? 3.
Gilbert Simondon Gilbert Simondon, né le 2 octobre 1924 à Saint-Étienne et mort le 7 février 1989 à Palaiseau, est un philosophe français du XXe siècle. Il est spécialiste de la théorie de l'information, de philosophie de la technique, de psychologie et d'épistémologie. Il est connu pour ses deux thèses, Du mode d'existence des objets techniques et L'individuation à la lumière des notions de forme et d'information. Le reste de son œuvre consiste en de nombreux articles, cours et conférences. Biographie[modifier | modifier le code] Famille[modifier | modifier le code] Formation[modifier | modifier le code] Gilbert Simondon fait ses études secondaires au lycée Claude-Fauriel de Saint-Étienne, sa ville natale, et a tôt l’occasion de fréquenter le milieu industriel, de discuter avec des ingénieurs, de s’intéresser à l’invention scientifique et technologique et à la manière dont les innovations sont reçues au sein de la société[1]. Enseignement et recherche[modifier | modifier le code]
Sème antique : la guerre du sens est déclarée. La recherche sémantique est l'un des derniers graals de l'industrie du "search". Chaque annonce dans ce domaine est suivie de près, particulièrement quand elle provient du leader Google. Lequel vient donc d'officialiser le lancement de son "knowkedge graph", qui se veut davantage une sémantisation explicite des pages de résultats associés à une requête plutôt qu'un "vrai" moteur de recherche sémantique. Des requêtes dans tous les sens. Le théorème du jaguar. Du point de vue des moteurs de recherche, la quête sémantique est d'abord là pour améliorer le service aux usagers en optimisant (et en automatisant) le processus de désambiguïsation lexicale. Le dilemme du prisonnier. Illustration. La recherche "sémantique" m'affiche, en colonne de droite, un encadré "sémantisé", c'est à dire qui me propose une structuration sous-jacente à ce que doivent être les informations minimales fournies à un usager déposant une requête sur un groupe de musique : La fabrique de la sémantique. Et plus loin :
40 ans d’interaction homme-machine : points de repère et perspectives Twitter : apports et limites pour le management des connaissances Le KM et les enjeux de socialisation depuis 20 ans Les années 90 ou l’impulsion décisive de Nonaka et Takeuchi Au milieu des années 90 le management des connaissances, popularisé sous l’acronyme « KM » (pour Knowledge Management), a connu un essor sous l’impulsion des travaux d’Ikujiro Nonaka et Hirotaka Takeuchi1. En mettant en lumière les spécificités liées aux connaissances tacites, Nonaka et Takeuchi introduisirent une véritable rupture dans la vision technicienne du KM tel qu’il se pratiquait alors dans les entreprises. Or, à cette époque, la pratique concrète du KM dans les entreprises était encore limitée à la « génération bases de données » (Bouvard & Storhaye, 2002). Les années 2000 ou l’ambition de la coopération L’émergence et la démocratisation des technologies issues de l’Internet apparurent alors vers les années 2000 comme le moyen privilégié, auparavant manquant, permettant de matérialiser les deux principes suggérés par Nonaka et Takeuchi. Ouverture et diversité Quinn, J.
DVD Le DVD I Structure DVD Vidéo I Structure DVD AVCHD I Encodage I Créer DVD I Liens Un DVD (Digital Vidéo Disc) peut se déteriorer. Sa durée de vie est estimée à 30 ans selon National Institute of Standards and Technology La précaution est d'en faire, comme pour tout autre support, une sauvegarde. Coupe d'un DVD +/-R Il y a 3 standards concurrents et incompatibles de DVD (ré)enregistrables : - DVD -R, DVD +R (R pour Recordable : enregistrable) - DVD -RW, DVD +RW (RW pour ReWritable : réinscriptible) 1 - DVD -R et DVD -RW Les DVD -R et -RW doivent être finalisés pour la lecture sur un lecteur de salon. 2 - DVD +R et DVD +RW Le DVD +R/RW a de meilleures spécifications techniques que le DVD -R/RW. Le DVD +R/RW est compatible avec tous les lecteurs de salon et de PC sortis après 2005. DVD -RAM est le meilleur format réenregistrable de DVD mais il est incompatible avec la plupart des lecteurs de salon et de PC. Principales capacités de DVD : Caracrtéristiques des DVD VTS_01_3.VOB Titre 01, VOB3 qualité