
Decomposing Twitter (Database Perspective) Twitter - one of the latest and hottest Web 2.0 trends used by millions of users around the world every day. How does it manage the enormous data produced by its users? This article reviews the technical aspects of the Twitter service, how it handles such a tremendous amount of tweets and other data, and looks at what we can learn from the findings. Twitter As we all know, Twitter, which launched its service in 2006, is expanding at an amazing pace. According to official About Twitter page, as of September 2010 some 175 million users use the service, generating about 95 million tweets a day. Simply put, the scale of service is amazing, but what is even more amazing is its growth rate. Understanding Twitter For those of us who are satisfied with sitting in the passenger seat, here is a brief outline of the services provided by Twitter. Twitter is a micro blogging service. Here are two core services of Twitter: Real-Time Data in Twitter Tweets However, there is a problem with this method.
Data Wrangler UPDATE: The Stanford/Berkeley Wrangler research project is complete, and the software is no longer actively supported. Instead, we have started a commercial venture, Trifacta. For the most recent version of the tool, see the free Trifacta Wrangler. Why wrangle? The R Project for Statistical Computing Apache Drill Speed is Key Leveraging an efficient columnar storage format, an optimistic execution engine and a cache-conscious memory layout, Apache Drill is blazing fast. Coordination, query planning, optimization, scheduling, and execution are all distributed throughout nodes in a system to maximize parallelization. Liberate Nested Data Perform interactive analysis on all of your data, including nested and schema-less. Flexibility Strongly defined tiers and APIs for straightforward integration with a wide array of technologies. Disclaimer Apache Drill is an effort undergoing incubation at The Apache Software Foundation sponsored by the Apache Incubator PMC.
HP Vertica Analytics Platform HP Vertica Analytics Platform The latest release of HP Vertica, codenamed “Dragline”, offers organizations new and faster ways to store, explore and serve more data. With the Dragline release, we’ve made HP Vertica even more powerful, allowing you to: HP Vertica “Dragline” addresses the needs of the most demanding, analytic- driven organizations by providing new features, including: HP Vertica Dragline lets organizations store data in a cost-effectively, explore it quickly and leverage well-known SQL-based tools to get customer insights. Recommended Resources How to Fix Location-Based People Discovery Philip Cortes is co-founder of people discovery startup Meeteor. Follow him on Twitter @philipcortes. No clear winner came out of South by Southwest’s battle of people discovery apps. Highlight seems to have received the best press, and according to Robert Scoble, about 5% of SXSW used the service. Despite this buzz, the consensus was that all of these services fell short of expectations. Why did these apps fail? 1) Lack of Single-Player Mode. 2) Not Capturing Intent. The social overlap between users can act as the lubricant that facilitates meeting, but it alone won’t compel two strangers to meet. 3) Transparent Privacy Settings. 4) Pick a Niche. 5) Mimic Offline Behavior. All five of these solutions don’t have to be solved perfectly in order for one app or web service to win the race.
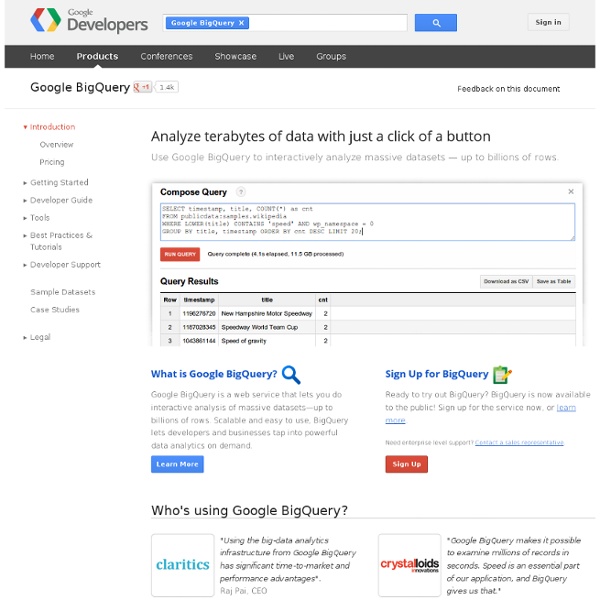
OpenRefine Gapminder: Unveiling the beauty of statistics for a fact based world view. Drill Drill Overview Apache Drill is an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets. Drill is the open source version of Google's Dremel system which is available as an IaaS service called Google BigQuery. One explicitly stated design goal is that Drill is able to scale to 10,000 servers or more and to be able to process petabyes of data and trillions of records in seconds. Currently, Drill is incubating at Apache. High Level Concept There is a strong need in the market for low-latency interactive analysis of large-scale datasets, including nested data (eg, JSON, Avro, Protocol Buffers). In recent years open source systems have emerged to address the need for scalable batch processing (Apache Hadoop) and stream processing (Storm, Apache S4). It is worth noting that, as explained by Google in the original paper, Dremel complements MapReduce-based computing. The Apache Drill team uses Chronon for testing.
State Street’s Chief Scientist on How to Tame Big Data Using Semantics Semantic databases are the next frontier in managing big data, says State Street's David Saul. Financial institutions are accumulating data at a rapid pace. Between massive amounts of internal information and an ever-growing pool of unstructured data to deal with, banks' data management and storage capabilities are being stretched thin. But relief may come in the form of semantic databases, which could be the next evolution in how banks manage big data, says David Saul, Chief Scientist for Boston-based State Street Corp. The semantic data model associates a meaning to each piece of data to allow for better evaluation and analysis, Saul notes, adding that given their ability to analyze relationships, semantic databases are particularly well-suited for the financial services industry. "Our most important asset is the data we own and the data we act as a custodian for," he says. Using a semantic database, each piece of data has a meaning associated with it, says Saul. More Insights
Gephi, an open source graph visualization and manipulation software The Seven S Model in PowerPoint 2010 McKinsey 7S model is a business diagram that involves seven interdependent factors which are categorized as either “hard” or “soft” elements. The seven elements in a 7S model includes: Strategy, Structure, Systems, Shared Values, Skills, Style, Staff. Hard elements are easier to define or identify and management can directly influence them. These are strategy statements; organization charts and reporting lines; and formal processes and IT systems. On the other hand, Soft elements can be more difficult to describe, and are less tangible and more influenced by culture. The way the model is presented in the image below shows the interdependence of the elements and indicates how a change in one affects all the others. In PowerPoint we can create The Sevel S Model by using hexagon shape and then interconnecting the shapes with lines. To connect the lines in McKinsey 7S model you can use the draw mode in PowerPoint. Finally you can right click on each object to add the text. Loading ...
AWS | Amazon Redshift – Cloud Data Warehouse Solution It’s never been easier to get file data into Amazon Redshift, using AWS Lambda. You simply push files into a variety of locations on Amazon S3 and have them automatically loaded into your Amazon Redshift clusters. Read more in A Zero-Administration Amazon Redshift Database Loader (April 2015). Amazon Redshift delivers fast query performance by using columnar storage technology to improve I/O efficiency and parallelizing queries across multiple nodes. Amazon Redshift has custom JDBC and ODBC drivers that you can download from the Connect Client tab of our Console, allowing you to use a wide range of familiar SQL clients. Amazon Redshift’s data warehouse architecture allows you to automate most of the common administrative tasks associated with provisioning, configuring and monitoring a cloud data warehouse. Security is built-in. Amazon Redshift uses a variety of innovations to obtain very high query performance on datasets ranging in size from a hundred gigabytes to a petabyte or more.