
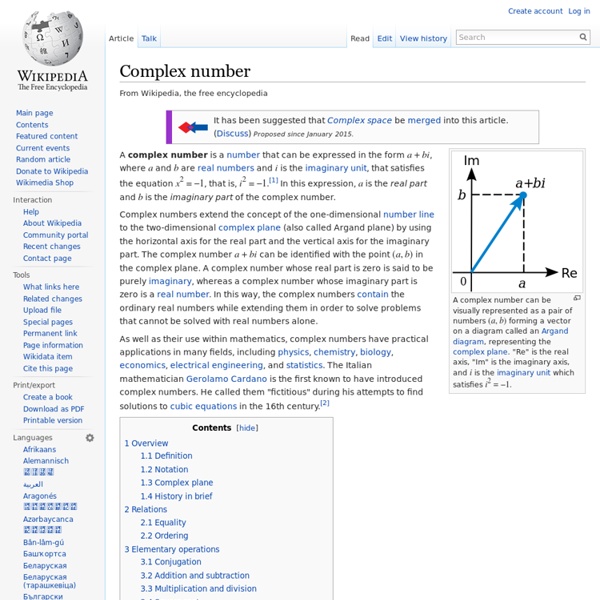
Vieta's formulas In mathematics, Vieta's formulas are formulas that relate the coefficients of a polynomial to sums and products of its roots. Named after François Viète (more commonly referred to by the Latinised form of his name, Franciscus Vieta), the formulas are used specifically in algebra. The Laws[edit] Basic formulas[edit] Any general polynomial of degree n (with the coefficients being real or complex numbers and an ≠ 0) is known by the fundamental theorem of algebra to have n (not necessarily distinct) complex roots x1, x2, ..., xn. Equivalently stated, the (n − k)th coefficient an−k is related to a signed sum of all possible subproducts of roots, taken k-at-a-time: for k = 1, 2, ..., n (where we wrote the indices ik in increasing order to ensure each subproduct of roots is used exactly once). The left hand sides of Vieta's formulas are the elementary symmetric functions of the roots. Generalization to rings[edit] belong to the ring of fractions of R (or in R itself if 's are computed from the 's. and
Complex plane Geometric representation of z and its conjugate z̅ in the complex plane. The distance along the light blue line from the origin to the point z is the modulus or absolute value of z. The angle φ is the argument of z. In mathematics, the complex plane or z-plane is a geometric representation of the complex numbers established by the real axis and the orthogonal imaginary axis. It can be thought of as a modified Cartesian plane, with the real part of a complex number represented by a displacement along the x-axis, and the imaginary part by a displacement along the y-axis.[1] Notational conventions[edit] In complex analysis the complex numbers are customarily represented by the symbol z, which can be separated into its real (x) and imaginary (y) parts, like this: for example: z = 4 + 5i, where x and y are real numbers, and i is the imaginary unit. In the Cartesian plane the point (x, y) can also be represented in polar coordinates as where Stereographic projections[edit] Cutting the plane[edit]
Matrix (mathematics) Each element of a matrix is often denoted by a variable with two subscripts. For instance, a2,1 represents the element at the second row and first column of a matrix A. Applications of matrices are found in most scientific fields. In every branch of physics, including classical mechanics, optics, electromagnetism, quantum mechanics, and quantum electrodynamics, they are used to study physical phenomena, such as the motion of rigid bodies. The numbers, symbols or expressions in the matrix are called its entries or its elements. The size of a matrix is defined by the number of rows and columns that it contains. Matrices are commonly written in box brackets: An alternative notation uses large parentheses instead of box brackets: The entry in the i-th row and j-th column of a matrix A is sometimes referred to as the i,j, (i,j), or (i,j)th entry of the matrix, and most commonly denoted as ai,j, or aij. Sometimes, the entries of a matrix can be defined by a formula such as ai,j = f(i, j).
Imaginary unit i in the complex or cartesian plane. Real numbers lie on the horizontal axis, and imaginary numbers lie on the vertical axis There are in fact two complex square roots of −1, namely i and −i, just as there are two complex square roots of every other real number, except zero, which has one double square root. In contexts where i is ambiguous or problematic, j or the Greek ι (see alternative notations) is sometimes used. For the history of the imaginary unit, see Complex number: History. Definition[edit] With i defined this way, it follows directly from algebra that i and −i are both square roots of −1. Although the construction is called "imaginary", and although the concept of an imaginary number may be intuitively more difficult to grasp than that of a real number, the construction is perfectly valid from a mathematical standpoint. Similarly, as with any non-zero real number: i and −i[edit] and are solutions to the matrix equation Proper use[edit] (incorrect). (ambiguous). Similarly: Powers[edit]
Mathematical induction Mathematical induction can be informally illustrated by reference to the sequential effect of falling dominoes. Mathematical induction is a method of mathematical proof typically used to establish a given statement for all natural numbers. It is done in two steps. The first step, known as the base case, is to prove the given statement for the first natural number. The second step, known as the inductive step, is to prove that the given statement for any one natural number implies the given statement for the next natural number. Although its namesake may suggest otherwise, mathematical induction should not be misconstrued as a form of inductive reasoning (also see Problem of induction). History[edit] An implicit proof by mathematical induction for arithmetic sequences was introduced in the al-Fakhri written by al-Karaji around 1000 AD, who used it to prove the binomial theorem and properties of Pascal's triangle. Description[edit] Example[edit] Algebraically: Axiom of induction[edit]
Euler's formula This article is about Euler's formula in complex analysis. For Euler's formula in algebraic topology and polyhedral combinatorics see Euler characteristic. Euler's formula, named after Leonhard Euler, is a mathematical formula in complex analysis that establishes the fundamental relationship between the trigonometric functions and the complex exponential function. Euler's formula states that, for any real number x, Euler's formula is ubiquitous in mathematics, physics, and engineering. History[edit] It was Johann Bernoulli who noted that[3] And since the above equation tells us something about complex logarithms. Bernoulli's correspondence with Euler (who also knew the above equation) shows that Bernoulli did not fully understand complex logarithms. Meanwhile, Roger Cotes, in 1714, discovered that ("ln" is the natural logarithm with base e).[4] Applications in complex number theory[edit] where the real part the imaginary part atan2(y, x) . and that both valid for any complex numbers a and b. . . and
Radius of convergence Definition[edit] For a power series ƒ defined as: where cn is the nth complex coefficient, and z is a complex variable. The radius of convergence r is a nonnegative real number or ∞ such that the series converges if and diverges if In other words, the series converges if z is close enough to the center and diverges if it is too far away. Finding the radius of convergence[edit] Two cases arise. then you take certain limits and find the precise radius of convergence. Theoretical radius[edit] The radius of convergence can be found by applying the root test to the terms of the series. "lim sup" denotes the limit superior. and diverges if the distance exceeds that number; this statement is the Cauchy–Hadamard theorem. The limit involved in the ratio test is usually easier to compute, and when that limit exists, it shows that the radius of convergence is finite. This is shown as follows. That is equivalent to Practical estimation of radius[edit] Domb–Sykes plot of the function as a function of index . by
Avogadro constant Previous definitions of chemical quantity involved Avogadro's number, a historical term closely related to the Avogadro constant but defined differently: Avogadro's number was initially defined by Jean Baptiste Perrin as the number of atoms in one gram-molecule of hydrogen. It was later redefined as the number of atoms in 12 grams of the isotope carbon-12 and still later generalized to relate amounts of a substance to their molecular weight.[4] For instance, to a first approximation, 1 gram of hydrogen, which has a mass number of 1 (atomic number 1), has 6.022×1023 hydrogen atoms. Similarly, 12 grams of carbon 12, with the mass number of 12 (atomic number 6), has the same number of carbon atoms, 6.022×1023. Avogadro's number is a dimensionless quantity and has the numerical value of the Avogadro constant given in base units. The Avogadro constant is fundamental to understanding both the makeup of molecules and their interactions and combinations. History[edit] [dubious ] Measurement[edit]
Kepler conjecture The Kepler conjecture, named after the 17th-century German mathematician and astronomer Johannes Kepler, is a mathematical conjecture about sphere packing in three-dimensional Euclidean space. It says that no arrangement of equally sized spheres filling space has a greater average density than that of the cubic close packing (face-centered cubic) and hexagonal close packing arrangements. The density of these arrangements is slightly greater than 74%. In 1998 Thomas Hales, following an approach suggested by Fejes Tóth (1953), announced that he had a proof of the Kepler conjecture. Background[edit] Diagrams of cubic close packing (left) and hexagonal close packing (right). Imagine filling a large container with small equal-sized spheres. Experiment shows that dropping the spheres in randomly will achieve a density of around 65%. The Kepler conjecture says that this is the best that can be done—no other arrangement of spheres has a higher average density. Origins[edit] Nineteenth century[edit]
Solution of the Poincaré conjecture By contrast, neither of the two colored loops on this torus can be continuously tightened to a point. A torus is not homeomorphic to a sphere. Every simply connected, closed 3-manifold is homeomorphic to the 3-sphere. An equivalent form of the conjecture involves a coarser form of equivalence than homeomorphism called homotopy equivalence: if a 3-manifold is homotopy equivalent to the 3-sphere, then it is necessarily homeomorphic to it. The Poincaré conjecture, before being proven, was one of the most important open questions in topology. History[edit] Poincaré's question[edit] At the beginning of the 20th century, Henri Poincaré was working on the foundations of topology—what would later be called combinatorial topology and then algebraic topology. In the same paper, Poincaré wondered whether a 3-manifold with the homology of a 3-sphere and also trivial fundamental group had to be a 3-sphere. The original phrasing was as follows: Attempted solutions[edit] Dimensions[edit] Solution[edit]
Tangent Tangent to a curve. The red line is tangential to the curve at the point marked by a red dot. Tangent plane to a sphere As it passes through the point where the tangent line and the curve meet, called the point of tangency, the tangent line is "going in the same direction" as the curve, and is thus the best straight-line approximation to the curve at that point. The word tangent comes from the Latin tangere, to touch. History[edit] The first definition of a tangent was "a right line which touches a curve, but which when produced, does not cut it".[1] This old definition prevents inflection points from having any tangent. Pierre de Fermat developed a general technique for determining the tangents of a curve using his method of adequality in the 1630s. Leibniz defined the tangent line as the line through a pair of infinitely close points on the curve. Tangent line to a curve[edit] At each point, the line is always tangent to the curve. Analytical approach[edit] Intuitive description[edit] by but If