Médiathèque de la Communauté d'Agglomération Sarreguemines Confluences - Un site utilisant Réseau UnPointZero MU
Veille facile avec les flux RSS sur Firefox – François MAGNAN – Formateur Consultant
Mise à jour du 26/02/2016 : Google Reader signalé plus bas comme lecteur de flux RSS performant n’existe plus. Parmi ses remplaçants, vous pouvez vous orienter vers QuiteRSS, voir cet article de mon blog à son sujet. Vos besoins en information sont permanents, vous souhaitez ne recevoir que ce qui vous intéresse ? Les flux RSS permettent de recevoir de façon continue des informations spécialisées comme les actualités d’un site ou d’une organisation, des communiqués de presse, le sommaire d’une revue. Pour qu’ils puissent apporter un réel gain, ce tutoriel concernera autant le répérage et la sélection des flux que leur gestion. Les logiciels utilisés se nomment « agrégateurs RSS » : ils permettent de réunir en un seul lieu les flux. Complémentaire du billet, la vidéo comporte des démonstrations 1/ Qu’est-ce qu’un flux RSS, en quoi c’est utile ? Comment trouver les flux importants ? 2/ Utiliser les flux RSS sur Firefox, sans installer d’extension. Il est souvent signalé par une icône orange
Le blog du CCSD | Centre pour la Communication Scientifique Directe
Impact des bibliothèques
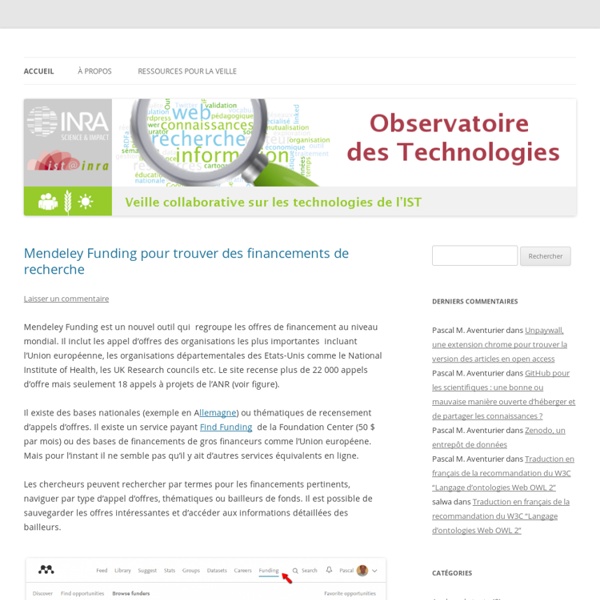
Les budgets aux politiques publiques sont remis en question d’où un développement de l’évaluation. Cette étude s’intéresse aux impacts de la bibliothèque du point de vue de l’activité économique, de l'inclusion sociale, du développement éducatif et culturel. L'étude d'impact " La bibliothèque vaut-elle le coût ? " a donné de nombreux résultats, certains plus inattendus que d'autres. Nous avons pu mettre en relief des impacts plus ou moins surprenants de la fréquentation de la bibliothèque.
[IDnum.] Ingénierie du Document NUMérique
L’élaboration du Plan de veille est présentée sous la forme d’une étude de cas sur le sujet suivant: « Évolution de la législation européenne des assurances » 1. Contexte de la demande : Le client est un groupe d’assurances. Le système de veille proposée devrait permettre d’alimenter en information une cellule de lobbying auprès du Conseil européen de l’assurance. Au sein de l’UE, 3 des 27 Directives Générales préparées par la Commission intéressent les activités du groupe : Þ DG « marché intérieur » (internal market)Þ DG de la concurrence (Compétition)Þ DG de la consommation (Consumer) Il faudra également surveiller la thématique des Instruments financiers, notamment les directives IMD et MIFID ainsi que les activités liées au domaine des assurances des Commissaire européens : Þ Charlie Mc Creevy (marché intérieur)Þ Meglena Kuneva (consummation)Þ Neelie Kroes (concurrence) 2. 3. 4. Les sources formelles à cibler doivent permettre de fournir des informations fiables de manière régulière: 5.
L'Alambic numérique | Le blog de la bibliothèque numérique de Clermont-Ferrand
Prospectibles
L’annonce de Mark Zuckerberg en fin d’année dernière n’a pas véritablement surpris les spécialistes. En renommant son entreprise « Meta » et en transformant les différents services numériques en un ‘métavers’, le patron de Facebook ne fait que suivre une tendance que d’autres acteurs du numérique ont déjà anticipée, notamment dans le monde des jeux en ligne. Qu’est-ce donc que cet univers où tout un chacun pourraient s’adonner à ses activités (échanger, consommer, se distraire) sur un mode virtuel et sous la forme d’un avatar ? A la faveur du confinement dû à la pandémie, un certain nombre d’activités et d’événements étaient passé sur la scène virtuelle et de nombreuses plateformes proposaient de transformer leurs services. Outre les jeux en ligne (Fortnite d’Epic Games, Animal crossing, GTA), le télé-enseignement et le télétravail ouvraient des classes et des salles de réunion virtuelles, où parents et enfants se partageaient la bande passante ! Premières expériences L’interopérabilité
Nous vous présentons les outils bien en main et gratuits pour la publication et l'échange d'information.
HTTBU
J’ai décrit dans un précédent billet le contenu de HAL-Unice, en terme de volumétrie. Rappelons que les constatations sont faites pour le corpus constaté, c’est-à-dire les archives déposées dans HAL, et les articles signalés par les chercheurs dans HAL. Ce corpus ne prend donc en compte ni l’ensemble de la publication scientifique de l’Universiténi même l’ensemble de la politique d’open access des structures de recherche de l’Université, car il existe d’autres dépôts d’archives en France et dans le monde Si les archives déposées dans ArXiv par des chercheurs français se retrouvent automatiquement dans HAL, ce n’est pas le cas par exemple de CiteSeerx, dans lequel on trouvera de nombreux articles déposés par des chercheurs affiliés à l’Université de Nice, qui ne sont pas du tout signalés dans HAL. Pour les archives qui y sont déposées ou signalées, HAL-Unice constitue-t-il un bon corpus pour donner à voir toutes les collaborations entre laboratoires et structures de recherche ? 1. 2.
Qu’est-ce que le Bouillon ? at Le bouillon des bibliobsédés
Le Bouillon des Bibliobsédés est destiné à tous ceux qui s’intéressent aux apprentissages en réseaux et qui souhaitent mieux comprendre les mutations engendrées par le numérique. Il est proposé par des professionnels de l’information et de la documentation (documentalistes, archivistes, bibliothécaires, journalistes, informaticiens, consultants) Le Bouillon des bibliobsédés entend susciter pour les thèmes qui entrent dans sa ligne éditoriale des conversations par une très large dissémination des liens jugés pertinents par les veilleurs, pour un usage personnel ou collectif. Le Bouillon est cuisiné par des veilleurs attentifs à diffuser des articles de qualité, pour vous. Le bouillon existe en 2 versions, tous les liens pour s’abonner sont dans la colonne de droite : Le Bouillon a été crée et diffusé en 2008 par Silvère Mercier, alias Silvae, alias le Bibliobsédé avant de devenir un projet collectif. Le Bouillon est un concept, un service, un flux, une conversation.