Mind Mapping : simplicité de la carte
Voici la suite de l’interview de Jean-Pascal Côte. Le Mind Mapping est un outil simple et ludique. Pour garder son efficacité, il est important que cette simplicité apparaisse dans la carte. C’est quoi pour toi une carte simple ? Ce n’est pas une question facile car elle en induit naturellement une autre : « Qu’est-ce qu’une carte compliquée ? ». En première approche on pourrait dire qu’une carte est compliquée quand elle présente les caractéristiques suivantes : Trop grande abondance d’informations (Infobésité)Manque de clarté (Nuance dans les couleurs, fontes, etc.)Mauvaise utilisation de l’espace (Les styles)Mauvaise utilisation des composants graphiques (Liens mentaux, entourages, bulles de commentaires, icones, images, etc.)Arborescence trop importanteManque de sens des motsDéfaut de cohérence dans la hiérarchisation des mots clefs de premier niveauEtc. A l’opposé on pourrait dire qu’une carte est simple quand elle respecte les points suivants : Mes cartes sont-elles simples ? Cindy
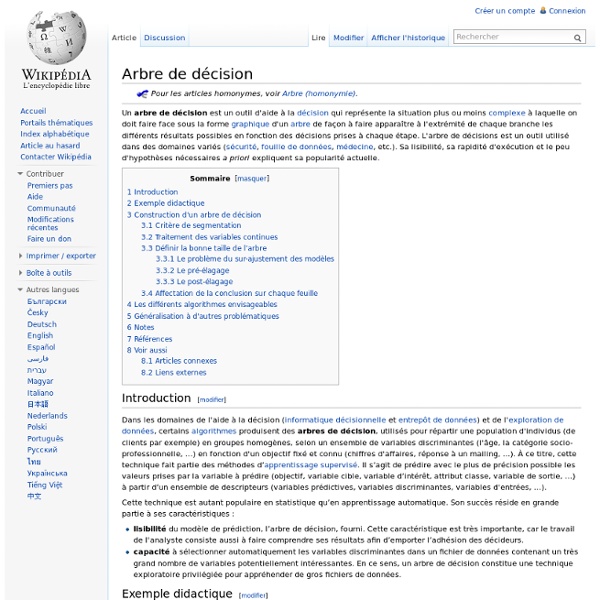
Diagramme d'Ishikawa (causes et effets)
Un article de Wikipédia, l'encyclopédie libre. Le Diagramme de causes et effets, ou diagramme d'Ishikawa, ou diagramme en arêtes de poisson ou encore 5M, est un outil développé par Kaoru Ishikawa en 1962[1] et servant dans la gestion de la qualité. Description et fonctions[modifier | modifier le code] Ce diagramme représente de façon graphique les causes aboutissant à un effet. Il peut être utilisé comme outil de modération d'un remue-méninges et comme outil de visualisation synthétique et de communication des causes identifiées. Ce diagramme se structure habituellement autour du concept des 5 M. Chaque branche reçoit d'autres causes ou catégories hiérarchisées selon leur niveau de détail. Le positionnement des causes met en évidence les causes les plus directes en les plaçant les plus proches de l'arête centrale. Variantes[modifier | modifier le code] Les termes « Moyens » ou « Machines » remplacent parfois la catégorie « Matériel ». Notes et références[modifier | modifier le code]
Points de Vente.fr - Le magazine de la distribution et du commerce
lsa-conso
En 2012, tous circuits confondus, il s’était vendu 400 millions de litres de nectars. En 2013, leurs ventes sont tombées à 287 millions de litres, selon l'association des professionnels du jus de fuits, Unijus qui prévoit que d’ici quelques années, les nectars de commodités disparaitront du marché. Seuls resteront les nectars valorisés, ceux à l’abricot, à la pêche ou encore à la banane. Les Français, fans de pur jus Les nectars ne représentent plus que 17,6% du marché contre 48,9% pour les pur jus (800,6 milions de litres, +1,83% versus 2012) et 33% pour les jus à base de concentré (540,1 millions de litres, -3,15%). « La France est un marché de pur jus, ce qui est atypique en Europe, explique Emmanuel Vasseneix, président d’Unijus. En 2013, la consommation globale de jus de fruits s’est élevée à 1,64 milliard de litres, soit 25 litres par habitant et par an.
Facebook et YouTube en tête des sites les plus visités au bureau !
> > > Facebook et YouTube en tête des sites les plus visités au bureau ! Olfeo vient de publier son étude annuelle sur l’utilisation d’Internet sur le lieu de travail, une étude qui dévoile que les français y ont augmenté leur temps de surf de 11 minutes par rapport à 2012. Désormais, ce sont en moyenne 108 minutes par personnes et par jour qui sont consacrées à la navigation sur Internet. Mais le plus alarmant concerne le temps que ces employés consacrent à leur utilisation personnelle. En effet, pas moins de 58% de ces minutes passées sur Internet, soit 63 minutes, seraient réservées à l’utilisation de Facebook, YouTube, Wikipedia ou encore Le Bon Coin. Olfeo note que les catégories les plus visitées sont les blogs, forums et Wiki (17%), les sites e-commerce (15%) et les réseaux sociaux (12%). Selon l’étude, la productivité d’un salarié chuterait de 14% en moyenne. La réalité de l’utilisation d’Internet au bureau, par Olfeo. Crédits photos : Rock1997 Partager cet article Inactif