
Lean Data Driven Product Development. Big data is variously applicable and used in many industrial sectors.
The idea of data creating business value is not new. But how do you make use of this data? What impact does it have on your product development? Save the date for October 15th and find out how product development is based on big data. The Big Data Community Alliance invited special speakers who have many years of experience in the field of data-driven product development. Who you can expect to meet: End users, business decision makers, IT decision makers from leading organizations in Germany Our event is entirely sales, marketing and product placement free as speakers are end users and practitioners from leading organizations in Germany.
Daniel Bartl sur Twitter : "Auf der Suche nach leidenschaftlichen Geeks für @comSysto #IKOM #java #angularjs #bigdata. Wir wollen die Spielregeln ändern. Big Data Applications with Spring XD - Lightweight Java User Group München (München) Comsysto : Come see the monkey in action... Strata Conference London – The European way of dealing with Big Data. It was a pleasure for comSysto to be part of the Strata Conference London 2013 from November 11th – 13th 2013.
Around 1000 mostly European people met in the London Hilton Metropole hotel to follow a conference excellently organised by O’Reilly. There was great food and a lot of staff supporting you finding your way to the presentation areas. Unfortunately, the five rooms were spread across two buildings and thus participants were forced to walk around a lot. That wasn’t that bad though, since walking cleared our heads. Stream your data into BigQuery in real-time. Posted by Ju-kay Kwek, BigQuery Product Manager Today, we live in a world where businesses are generating large amounts of real-time data from web applications that serve millions of users, online sales transactions, or customer activity created by an explosion of connected devices.
Being able to react quickly to changes in the data being generated is critical to remain competitive. Big Data: Smart Steps in action. Cultivating Hybrids: 4 Key Data Architectures for Scaling Infinitely. It is the destiny of current data stores to be scaled.

There is no way around it. You don’t even need a crystal ball or fortune teller to see this future. In this article, we will focus on the fundamental computer science behind horizontally scaling data stores and the limits of common approaches. Then, we will explain the architecture for a hybrid data platform—combining Hadoop, massively parallel processing databases (MPP), NewSQL, and NoSQL types of systems. Lastly, we will cover some real-world use cases and show how this reference architecture can scale with us into the years ahead. Horizontal Scale, a Definition A scalable system is one that allows throughput or performance to increase proportionally to the hardware added.
Still, there are challenges with horizontal scale, and we’ve seen a number of solutions show up in the market to help us achieve it. LinkedIn Corp (LNKD): Why LinkedIn Will Be A $300 Stock This Time Next Year. One of the most basic algorithms we used at both Geller Capital and Surfview Capital was the intersection between high revenue growth and companies that crushed their Wall Street EPS estimates quarter after quarter.

This combination was specifically powerful because it signaled that the market did not quite respect the ability for the company to drive incremental profit from their revenue, specifically quickly growing revenue. Accompanying this pattern was often a disregard for how large a market or opportunity that company had in front of it. It was also usually found in a new technology, or a business that was rapidly transitioning its model, Whole Foods Market (WFM) being a good example of the latter right now. Today, LinkedIn (LNKD) represents the former just about as well as a stock can.
In early January I wrote up LinkedIn as one of the 10 stocks to own this year. LinkedIn currently trades at about a 21 times revenue multiple. (click to enlarge) Is this author on the ball? Big data can help us make sense of absence. Comsysto : @cloudHPC talking about #R... Poll Results: Hadoop YARN vs. pre-YARN. Back in April 2013 there was a poll in Hadoop Users LinkedIn group: YARN or pre-YARN – which version of Hadoop are you using?
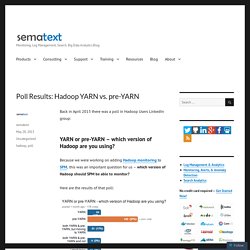
Because we were working on adding Hadoop monitoring to SPM, this was an important question for us – which version of Hadoop should SPM be able to monitor? Here are the results of that poll: As we can see, most Hadoop users are still using the old version of Hadoop and are not using YARN. The percentage in the “YARN” bar at the top is partially hidden, but it’s 13% — only 13% of Hadoop users who responded are using Hadoop YARN.
Sessiondetails: TDWI - The Data Warehousing Institute. Time: 10:00 - 13:15 Speaker: Markus Schmidberger Big Data is on every CIO's mind.
It is presently synonymous with open-source technologies like Hadoop, and the 'NoSQL' class of databases. Big Data and Data Science – what’s really new? Big Data is a hype.
It’s also a buzz word. Maybe a trend? Introducing Spring XD. Today we are officially kicking off a new initiative called Spring XD whose theme is "tackling Big Data complexity"1.
The Spring Data team has been incredibly busy over the past few years, not only providing support for NoSQL datastores but also simplifying the development experience with Hadoop. With the creation of the Spring for Apache Hadoop project, we made it easier to get started developing Hadoop applications by providing a rich configuration model and a consistent programming model across Hadoop ecosystem projects such as Hive and Pig. As Spring users would expect, one can: Configure and run MapReduce jobs as container managed objects.Use template helper classes for HDFS, HBase, Pig and Hive to remove boilerplate code from your applications. Spring for Apache Hadoop provides a strong foundation for building Hadoop applications. Deep Information Sciences Takes Big Data a Quantum Leap Forward. PORTSMOUTH, N.H.

--(BUSINESS WIRE)--Deep Information Sciences, Inc. (Deep) made its debut today with the introduction of its groundbreaking new general purpose database, DeepDB, and the announcement of $10 million in Series A funding to support the company’s strategy to transform the Big Data market. Enabling simultaneous transactions and analytics in real time on the same data set, DeepDB brings unprecedented scale, simplicity and speed to data-driven decision making at large organizations. “Our powerful technology, combined with our leadership bench strength, positions us for a fast path to market leadership in Big Data. We look forward to the opportunity to help our customers overcome the challenges of Big Data and seize competitive advantages through a next-generation approach to data management.”
Deep answers the needs of this evolving market with DeepDB, which has been built to support data-driven decision making at the highest levels of the enterprise. Apache CloudStack: Open Source Cloud Computing. Release. #BigData100: Vote Now for the Most Influential in Big Data - Saul Sherry. Google updates BigQuery with SQL-like queries, grouping of distinct values, and support for Timestamp data. Google on Thursday announced a slew of new features for Google BigQuery, its service for quickly analyzing large amounts of data, to let analytic teams deliver what organizations really need: “actionable and data-driven business insights.” In short, Google has added new capabilities to help businesses work effectively with large amounts of data over a greater range of query and data types.
Here are the three new features Google wants to highlight: Big JOIN: use SQL-like queries to join very large datasets at interactive speeds.Big Group Aggregations: perform groupings on large numbers of distinct values.Timestamp: native support for importing and querying Timestamp data. The new Big JOIN feature gives users the ability to produce a result set by merging data from two large tables by a common key: you can skip a data transformation step by simply specifying JOIN operations using SQL. Google has also added the ability to add new columns to existing BigQuery tables. Big Data Predictions For 2013. William Shakespeare wrote that “What’s past is prologue.” Big data surely builds on our rich past of using data to understand our world, our customers, and ourselves.
Now the world is flush and getting flusher in big data from cloud, mobile, and the Internet of things. What does it mean for enterprises? Tomassino : The human face of #bigdata... A programmer’s guide to big data: 12 tools to know — Data. What a Big-Data Business Model Looks Like - R “Ray” Wang. By R “Ray” Wang | 10:00 AM December 6, 2012 The rise of big data is an exciting — if in some cases scary — development for business. Together with the complementary technology forces of social, mobile, the cloud, and unified communications, big data brings countless new opportunities for learning about customers and their wants and needs. It also brings the potential for disruption, and realignment.
MLbase: A User-friendly System for Distributed Machine learning. Machine learning (ML) and statistical techniques are key to transforming big data into actionable knowledge. In spite of the modern primacy of data, the complexity of existing ML algorithms is often overwhelming—many users do not understand the trade-offs and challenges of parameterizing and choosing between different learning techniques. Furthermore, existing scalable systems that support machine learning are typically not accessible to ML researchers without a strong background in distributed systems and low-level primitives. To address these issues we are building MLbase, a novel system harnessing the power of machine learning for both end-users and ML researchers.
MLbase will ultimately provide functionality to end users for a wide variety of common machine learning tasks: classification, regression, collaborative filtering, and more general exploratory data analysis techniques such as dimensionality reduction, feature selection and data visualization. Big Data: Smart Steps in action. Big Data and analytics: Reg survey crunches the numbers.
High performance access to file storage Every IT professional understands that relational databases play an important role in most organisations. Indeed, the previous article in this series highlighted that such repositories are used to hold business critical data in many organisations. Such “traditional platforms” are not only widely deployed, they are also well understood, something that cannot be said for a number of more recent additions to information management armouries (Figure 1).
Indeed the chart above indicates that on average almost as many respondents have no familiarity with modern solutions such as scale-out storage, distributed search and indexing, WORM (Write Once, Read Many) databases, distributed data analytics and rules based stream processing as have a reasonable knowledge of them. New Advances in High Performance Analytics with R: ‘Big Data’ Decision Trees and Analysis of Hadoop Data.
Tomassino : #strataconf NYC keynote just... Tomassino : #strataconf NYC keynote just... Comsysto : #BigData Solyanka by @Bernd_Z... München MongoDB User Group (München. _juan_bernabe : @WayraDE sharing ideas around... Telefonica Wants To Turn Its Mobile Data Into A Big Data Business, Launches Dynamic Insights Unit. Why we’re all big data now — Data. IBM Introduces Mainframes for Big Data Age. By Angela Guess. Operational Intelligence: Real-Time Business Analytics for Big Data. Hype Cycle for Cloud Computing Shows Enterprises Finding Value in Big Data, Virtualization.
Infographic: Every Minute On The Internet (Somebody Accidentally Sees A Peen That They Didn't Mean To) Note: I was going to include a larger version so you could read that little paragraph at the top but 1. let's not kid ourselves, you hate reading and 2. I actually did spend the time to read it and it sucked. This is an infographic depicting the massive amount of information that's exchanged over the intertubes every minute.
It's not the first one of these I've written about because there's an older one HERE and an even older one than that HERE. Info - Latests News about MongoDB. Nearest neighbor models are conceptually just about the simplest kind of model possible. The problem is that they generally aren? T feasible to apply. Dilbert on Big Data « comSysto.com. Big Data explained in 10 movies. My father is an undisputed film lover and made my sister and me love the seventh art already in the early years of my life He quite often resorted to movie scenes to teach and explain us how to deal with certain situations in life. ComSysto.com. Mobile Business Intelligence: Innovations in Real Time. Monday Fun: Seven Databases in Song. MongoDB Presentations - MongoNYC 2012: Real Time Data Analytics; Pre-Aggregation with Counters (Advanced Session)
Strata Jumpstart 2011: DJ Patil, "Data Science and Building Data Teams"