
Civic Hacking with Python – Part 2 « syslogd.net. I apologize for the time it took before writing this part, but you know what they say: Better late then never.
In this part, I’ll explain how I extracted (scraped) the data from the Transports Quebec database mentioned in Part 1 using Python, Scrapy and a few other tools. This post is not a full-fledged tutorial on using Scrapy, but it should give you a place to start if you’d like to do something similar. In order to jump directly to the good stuff, I’ll skip the Scrapy installation and assume you are already familiar with Python.
Open Source Search Server. 12.1.
Data source configuration options Data source type. Mandatory, no default value. Known types are mysql, pgsql, mssql, xmlpipe2, tsvpipe, and odbc. All other per-source options depend on source type selected by this option. Example: type = mysql SQL server host to connect to. In the simplest case when Sphinx resides on the same host with your MySQL or PostgreSQL installation, you would simply specify "localhost".
Sql_host = localhost SQL server IP port to connect to. Sql_port = 3306 SQL user to use when connecting to sql_host. How to build a simple web crawler. If you're creating a search engine you'll need a way to collect documents.
In this excerpt from Tony Segaran's Programming Collective Intelligence the author shows you how to set up a simple web crawler using existing tools. Automation - Workflow for academic research projects, one-step builds, and the Joel Test. (3) What are some of the best books I learn programming from. Programming Collective Intelligence: Building Smart Web 2.0 Applications (9780596529321): Toby Segaran. (3) Book Recommendations: What are some good introductory books on network theory, particularly in the social sciences.
(3) What are some of the best books on Computer Science. Millennium Villages Project. The Millennium Villages Project is a project of the Earth Institute at Columbia University, the United Nations Development Programme, and Millennium Promise. It is an approach to ending extreme poverty and meeting the Millennium Development Goals—eight globally endorsed targets that address the problems of poverty, health, gender equality, and disease. The Millennium Villages aim to promote an integrated approach to rural development. By improving access to clean water, sanitation and other essential infrastructure such as education, food production, basic health care, and by focusing on environmental sustainability, Millennium Villages claims to ensure that communities living in extreme poverty have a real, sustainable opportunity to lift themselves out of the poverty trap.[1] Millennium Villages are divided into different types.
The project was initially funded through a combination of World Bank loans and private contributions, including $50 million from George Soros.[3] Critics[edit] BuzzFeed, the Ad Model for the Facebook Era? On a Tuesday in February, Matt Stopera, a 24-year-old senior editor at a website called BuzzFeed, saw something hilarious on Twitter.
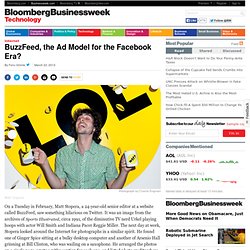
It was an image from the archives of Sports Illustrated, circa 1991, of the diminutive TV nerd Urkel playing hoops with actor Will Smith and Indiana Pacer Reggie Miller. The next day at work, Stopera looked around the Internet for photographs in a similar spirit. He found one of Ginger Spice sitting at a bulky desktop computer and another of Arsenio Hall grinning at Bill Clinton, who was wailing on a saxophone. He arranged the photos on a single page, wrote a pithy caption for each one, and listed photo credits where he could. At around 5 p.m., Stopera published “48 Pictures That Perfectly Capture the ’90s” on BuzzFeed. Upcoming Group Activities near San Diego. The Future of Magazines Should Look a Lot Like Spotify. By Hamish McKenzie On March 26, 2012 The options we have for reading magazine journalism in the digital format are pretty sad.
We live in an era of self-driving cars, augmented reality, and we can keep a map of the entire planet in our pocket, but we are stuck reading magazine journalism the way it has always been presented: in dead print load-dumped onto unfeeling pages, tied up into inseparable bundles (even if they are digital). Tablet computers may well be the saviors of magazines, but even in the face of declining circulations, magazines are doing little to save themselves. Magazine reading on tablets is proving to be almost as cumbersome as it is on paper, with an anachronistic page-turning mentality baked into the apps and a copied-and-pasted design lifted directly from the versions you buy at the drug store. But the worst part is the distribution. Take Apple’s Newsstand for the iPad. The first problem is that there is an app for each magazine. FamilyLeaf Brings Your Kin Together In Its Own Private Social Network.
Facebook is on its way to having a billion members, but it’s not always making friends everywhere it goes.
Two young men, both aged 19 and in the most recent crop of Y Combinator startups, think they’ve found a gap in the market that has yet to be served that well by the biggest social network: families. Check-In Needs To Work, But How Can We Fix It? Remember Highlight?
That app that everyone thought was hot stuff back at SXSW?