
Leaving Facebook... Adding Error Bars to Your Graph. Add-ErrBar-to-Graph There are several methods for plotting error bars in data plots, depending upon whether: You want to construct the bars using the values in a dataset.
You want Origin to draw the error bars by calculating some simple dataset statistics (%, SD, or Square Root). Using a dataset to supply error bar values Method 1: This method requires you to preset the worksheet's column Plot Designations prior to creating your plot. Set up your worksheet so that the columns are designated Y1, yEr1, Y2, yEr2, Y3, yEr3... Method 2: Use the Plot Setup (Origin workbook) dialog or the Select Data for Plotting (Excel workbook) dialog to plot a data set as error bars.
Method 3: Error bars also could be added in the 3D graph from existing datasets by the Plot Details dialog. It is possible to add error bars for 3D Bars, 3D Trajectory and 3D Scatter plots created from worksheet data, or 3D Surface, 3D Bars and 3D Scatter plots created from matrix data.
Bandes de Bollinger. Un article de Wikipédia, l'encyclopédie libre.
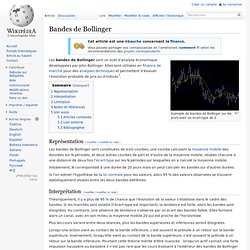
Exemple de bandes de Bollinger sur dix jours avec un écart-type de 2 Les bandes de Bollinger sont un outil d'analyse économique développées par John Bollinger. Elles sont utilisées en finance de marché pour des analyses techniques et permettent d'évaluer l'évolution probable de prix ou d'indices[1]. Représentation[modifier | modifier le code] Les bandes de Bollinger sont constituées de trois courbes, une courbe calculant la moyenne mobile des données sur N périodes, et deux autres courbes de part et d'autre de la moyenne mobile, situées chacune à une distance de deux fois l'écart-type sur les N périodes sur lesquelles on a calculé la moyenne mobile. Initialement, N correspondait à une durée de 20 jours mais on peut calculer les bandes sur d'autres durées.
Si l'on admet l'hypothèse de la loi normale pour les valeurs, alors 95 % des valeurs observées se trouvent statistiquement situées entre les deux bandes extrêmes. Analyse financière. Introduction (élémentaire) à la statistique. NOTE: ce document doit être lu avec un navigateur qui reproduit correctement les caractères grecs, sinon les formules seront totalement incompréhensibles.

Vérifiez ceci avec l'exemple suivant: alpha α, beta β, gamma γ, mu μ. Table (voir aussi "Index") I - Statistique descriptive 1 - définitions a - statistique de tendance centrale figure 1. Histogramme de 25 notes b - statistique de dispersion figure 1 bis. Histogramme de 12 notes 2 - calcul de la variance figure 2. Distinguer: les statistiques qui sont les " états " faits de lourds (illisibles) tableaux de chiffres, de la statistique, qui est une méthode de réduction et d'interprétation de ces tableaux. A - Statistique de tendance centrale (retour) En plus de la moyenne, il existe en réalité plusieurs autres statistiques de tendance centrale, par exemple la médiane, qui est la note qui divise toutes les autres en deux parties égales : il y a autant de notes inférieures à la médiane que de notes supérieures à la médiane. (figure 1. Chapitre 7 : Test d’hypothèse. Index thématique techniques quantitatives.
Mann-Whitney Test. For n a =0; n b =0.

In order to apply the Mann-Whitney test, the raw data from samples A and B must first be combined into a set of elements, which are then ranked from lowest to highest, including tied rank values where appropriate. These rankings are then re- sorted into the two separate samples. If your data have already been ranked, these ranks can be entered directly into the cells headed by the label «Ranks». In this case, please note that the sum of all ranks for samples A and B combined must be equal to If this equality is not satisfied, you will receive a message asking you to examine your data entry for errors. If your data have not yet been rank-ordered in this fashion, they can be entered into the cells labeled «Raw Data» and the ranking will be performed automatically.