
Retrieving objects efficiently. Retrieving objects efficiently. 2.3.2. Extended session and automatic versioning. 12.3.2.
Extended session and automatic versioning A single Session instance and its persistent instances that are used for the whole conversation are known as session-per-conversation. Hibernate checks instance versions at flush time, throwing an exception if concurrent modification is detected. It is up to the developer to catch and handle this exception. Common options are the opportunity for the user to merge changes or to restart the business conversation with non-stale data. The Session is disconnected from any underlying JDBC connection when waiting for user interaction. // foo is an instance loaded earlier by the old session Transaction t = session.beginTransaction(); // Obtain a new JDBC connection, start transaction foo.setProperty("bar"); session.flush(); // Only for last transaction in conversation t.commit(); // Also return JDBC connection session.close(); // Only for last transaction in conversation The foo object knows which Session it was loaded in.
Hibernate Criteria Example Tutorial. 06-Hibernate-Transaction Management and Automatic Versioning. Hibernate. Transactions and concurrency (Hibernate) In this topic, we finally talk about transactions and how you create and control units of work in a application.

We’ll show you how transactions work at the lowest level (the database) and how you work with transactions in an application that is based on native Hibernate, on Java Persistence, and with or without Enterprise JavaBeans. 06-Hibernate-Transaction Management and Automatic Versioning. Versioning & Optimistic Locking in Hibernate - Intertech Blog. By Jim White (Directory of Training and Instructor) A few weeks ago while teaching Hibernate, a student (thanks Dan) asked me about whether version numbers can be generated by the database.
The answer is – Yes, in some cases. I thought the question and an expanded discussion of Hibernate’s versioning property would be a good topic for this week’s blog entry. The <version> property (or @Version annotation) For those of you that use Hibernate today, you are probably aware that Hibernate can provide optimistic locking through a version property on your persistent objects. To specify a version for your persistent object, simply add a version (or timestamp) property in your mapping file and add a version attribute to your persistent class. For those using annotations, just mark the version property’s getter in the class with the @Version annotation.
@Version public long getVersion() { return version; } Optimizing Hibernate performance through lazy, fetch and batch-size settings. Posted on August 30th, 2012 in Uncategorized by Michael In this post, I am going to mostly focus on a particular example with our usage of Hibernate and how performance was improved.
We have a User object (who doesn’t?) , which maps to many Badge objects like so: <class name="com.utest.User"> ... <bag name="badges" table="Badges" lazy="false"></bag></class> Notice that lazy is set to false, because we need to make sure the User object is fully initialized before passing it out of the session context. Loading Users Now we want to load some users, say 67 of them, and we use HQL like this: from User where userId in (:userIds) unfortunately, this results in 68 queries (N+1 selects problem): 1 main query to load all the Users and then 67 queries to load badges for one user at a time.
One way we could try to optimize this is to add fetch=”join” to the mapping: we are hoping that Hibernate will now run a single query, with an outer join to the Badges table, but in practice it does not. Conclusions. Using Hibernate in a Web Application - NetBeans IDE Tutorial. In this tutorial, you use the NetBeans IDE to create and deploy a web application that displays data from a database.
The web application uses the Hibernate framework as the persistence layer for retrieving and storing plain old Java objects (POJOs) to a relational database. Hibernate is framework that provides tools for object relational mapping (ORM). The tutorial demonstrates how to add support for the Hibernate framework to the IDE and create the necessary Hibernate files. After creating the Java objects and configuring the application to use Hibernate, you create a JSF managed bean and JSF 2.0 pages to display the data. Before starting this tutorial you may want to familiarize yourself with the following documents. Contents To follow this tutorial, you need the following software and resources.
You can download a zip archive of the finished project. Creating the Database. JPA Performance, Don't Ignore the Database (Carol McDonald) Database Schema Good Database schema design is important for performance.
One of the most basic optimizations is to design your tables to take as little space on the disk as possible , this makes disk reads faster and uses less memory for query processing. Data Types You should use the smallest data types possible, especially for indexed fields. The smaller your data types, the more indexes (and data) can fit into a block of memory, the faster your queries will be. Normalization. Ejemplo de JPA , Introducción (I) - Arquitectura Java. JPA o Java Persistence API es el standard de Java encargado de automatizar dentro de lo posible la persistencia de nuestros objetos en base de datos .Sin embargo incluso a nivel básico genera dudas a los desarrolladores .
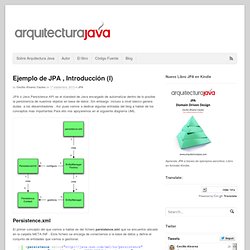
Así pues vamos a dedicar algunas entradas del blog a hablar de los conceptos mas importantes.Para ello nos apoyaremos en el siguiente diagrama UML. Persistence.xml El primer concepto del que vamos a hablar es del fichero persistence.xml que se encuentra ubicado en la carpeta META-INF . Este fichero se encarga de conectarnos a la base de datos y define el conjunto de entidades que vamos a gestionar. En nuestro caso unicamente tenemos una entidad “Persona” y luego la parte que se encarga de definir el acceso a la base de datos generando un pool de conexiones etc.