
ACL Anthology. Parsing English with 500 lines of Python « Computational Linguistics. Parsing English with 500 lines of Python A syntactic parser describes a sentence’s grammatical structure, to help another application reason about it.
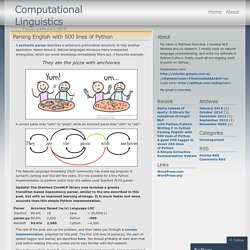
Natural languages introduce many unexpected ambiguities, which our world-knowledge immediately filters out. A favourite example: They ate the pizza with anchovies A correct parse links “with” to “pizza”, while an incorrect parse links “with” to “eat”: The Natural Language Processing (NLP) community has made big progress in syntactic parsing over the last few years. Update! The rest of the post sets up the problem, and then takes you through a concise implementation, prepared for this post. The Cython system, Redshift, was written for my current research.
Problem Description It’d be nice to type an instruction like this into your phone: Set volume to zero when I’m in a meeting, unless John’s school calls. And have it set the appropriate policy. Unless John’s school calls, when I’m in a meeting, set volume to zero Example usage: Projective trees. JournalTOCs. Use JournalTOCs API (Application Programming Interface) to create your own cool web applications that integrate content from freely available journal TOCs.

Most of JournalTOCs API calls are free and don't require any registration process. Developers can use the API to embed JournalTOCs' search functionality within their web applications. Anyone with access to RSS Readers can also use the JournalTOCs API. The API gives you access to our entire database of articles and journals aggregated from the publishers' TOC RSS feeds, as soon as they are published on the web. API's results are returned in RSS 1.0 format, which then you can parse and use in your own web application, RSS reader or institutional web page. API Base URL: Book. Natural Language Processing with Python – Analyzing Text with the Natural Language Toolkit Steven Bird, Ewan Klein, and Edward Loper This version of the NLTK book is updated for Python 3 and NLTK 3.

The first edition of the book, published by O'Reilly, is available at (There are currently no plans for a second edition of the book.) 0. 1. 2. 3. 4. [IT Services] - Indexing a Corpus with XAIRA: a Tutorial. In this exercise you will learn how to index your own corpus for use with Xaira.
![[IT Services] - Indexing a Corpus with XAIRA: a Tutorial](http://cdn.pearltrees.com/s/pic/th/services-indexing-tutorial-96138921)
Indexing is quite a complex process, and we will not try to cover all of the issues involved. The reference specification for the Xaira indexer is available online at the Xaira Tools Windows utility, which we will use in this exercise, also includes a Help file which should be consulted for more detailed information. The Xaira Tools Windows utility also has a ‘wizard’ interface, which can easily cope with the most common varieties of corpus. We'll demonstrate that by using it to build three different versions of the same corpus with increasing amounts of complex markup.
In the tutorial, we use as a sample corpus three different versions of Varney The Vampyre, a famous 19th century English popular novel. Download this archive, and unpack it into a temporary folder on your desktop. 1.1. Select `Index Wizard' command from the File menu The Corpus Name dialog opens. Your corpus is ready for use! 1.2. 1.3. Recognising Textual Entailment Challenge. New!

TAC 2008 Recognizing Textual Entailment (RTE) Track Recognising Textual Entailment Challenges Textual Entailment Recognition was proposed recently as a generic task that captures major semantic inference needs across many natural language processing applications, such as Question Answering (QA), Information Retrieval (IR), Information Extraction (IE), and (multi) document summarization. This task requires to recognise, given two text fragments, whether the meaning of one text is entailed (can be inferred) from the other text. The First Recognising Textual Entailment Challenge The first PASCAL Recognising Textual Entailment Challenge ( - ) provided the first benchmark for the entailment task. Challenge citation: Please use the following citation when referring to the RTE challenge:Ido Dagan, Oren Glickman and Bernardo Magnini.
RTE 1 Workshop Proceedings.
Geoffrey Sampson: Empirical Linguistics. Geoffrey Sampson by Geoffrey Sampson Linguistics has become an empirical science again, after several decades when it was preoccupied with speakers’ hazy “intuitions” about language structure. With a mixture of English-language case studies and more theoretical analyses, Empirical Linguistics gives an overview of some of the new findings and insights about the nature of language which are emerging from investigations of real-life speech and writing — often, though not always, using computers and electronic language samples (“corpora”). Empirical Linguistics brings concrete evidence to bear in resolving long-standing questions such as “Is there one English language or many Englishes?” , and “Do different social groups use characteristically elaborated or restricted language codes?”.
The book shows readers how to use some of the new techniques for themselves. Empirical Linguistics asks why the discipline lost its way in the closing 20th-century decades. Some critical comment: Chapter titles: