
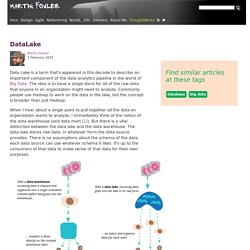
Untitled. Within a hybrid data warehouse architecture, as promoted in the Data Vault 2.0 Boot Camp training, a data lake is used as a replacement for a relational staging area.

Thus, to take full advantage of this architecture, the data lake is best organized in a way that allows efficient access within a persistent staging area pattern and better data virtualization. Figure 1: The Data Lake in a Hybrid Data Vault Architecture The data lake, as shown in figure 1, is used within the hybrid architecture as a persistent staging area (PSA).
This is different to relational staging in which a persistent or transient staging area (TSA) is used. As a TSA has the advantage that the needed effort for data management is reduced: e.g. if the source structure is changing, the relational stage table must be adjusted. Datenqualität messen: Mit 11 Kriterien Datenqualität quantifizieren. The 2 Types of Data Strategies Every Company Needs. More than ever, the ability to manage torrents of data is critical to a company’s success.

But even with the emergence of data-management functions and chief data officers (CDOs), most companies remain badly behind the curve. Cross-industry studies show that on average, less than half of an organization’s structured data is actively used in making decisions—and less than 1% of its unstructured data is analyzed or used at all. More than 70% of employees have access to data they should not, and 80% of analysts’ time is spent simply discovering and preparing data.
Now That You’ve Gone Swimming in the Data Lake – Then What? Image source: EMC Data Lakes are a new paradigm in data storage and retrieval and are clearly here to stay.

As a concept they are an inexpensive way to rapidly store and retrieve very large quantities of data that we think we want to save but aren’t yet sure what we want to do with. DataLake. Database · big data tags: Data Lake is a term that's appeared in this decade to describe an important component of the data analytics pipeline in the world of Big Data.
The idea is to have a single store for all of the raw data that anyone in an organization might need to analyze. Data: consistency vs. availability - Data Management & Decision Support. There is a fundamental choice to be made when data is to be 'processed': a choice between consistency vs. availability ora choice between work upstream vs. work downstream ora choice between a sustainable (long term) view vs. an opportunistic (short term) view on data Cryptic, I know.

Let me explain myself a bit. Let me take you on a short journey. Consistency vs. availability, I choose a for a position skewed towards consistency. If I choose consistency, I need to validate the data before it is processed, right? "But, but, but...we need the data What are the options? "But, but, but...we can't ask them that, they never change it, we gotta deal with the data as we receive it". Ah, so you want to process the data, despite the fact that it does not adhere to the logical model? You want to slide to the right on the spectrum of consistency vs. availability?
4 Quadrant Model for Data Deployment - Blog: Ronald Damhof. I have written numerous times about efficient and effective ways of deploying data in organizations.
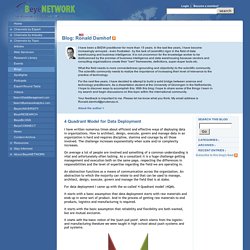
How to architect, design, execute, govern and manage data in an organization is hard and requires discipline, stamina and courage by all those involved. The challenge increases exponentially when scale and/or complexity increases. Data Wrangling, Information Juggling and Contextual Meaning, Part 2. The pragmatic definitions presented in part 1 of information as the subjectively interpreted record of personal experiences physically stored on (mostly) digital media, and data/metadata as information that has been modeled and “deconstructed” for ease of computer processing, offer an explanation as to why data wrangling or preparation can be so time-consuming for data scientists.

If the external material is in the form of data (for example, from devices on the Internet of Things), the metadata may be minimal or non-existent; the data scientist must then complete or deduce the context from any available metadata or the data values themselves. In the case of external, loosely structured information such as text or images, the data scientist must interpret the context from within the content itself and prior experience.
The importance of context for data wrangling (and, indeed, analysis) cannot be over-estimated. As seen above, context may exist both within formal metadata and elsewhere. Data Wrangling, Information Juggling and Contextual Meaning, Part 1. “Data wrangling is a huge—and surprisingly so—part of the job,” said Monica Rogati, vice president for data science at Jawbone, in a mid-2014 New York Times article by @SteveLohr that I came across recently.

“At times, it feels like everything we do.” With all due respects to Ms. Rogati, the only surprising thing about this is her surprise. Data wrangling, also previously known as data cleansing and integration, is as old as data warehousing itself. Older perhaps, than many data scientists in senior roles in the industry. A return to first principles is called for. From informatics to philosophy, there are many different definitions of both data and information, but let’s be pragmatic. This variability of meaning proved a challenge to the early builders of computer applications. But it’s actually more complex if we step beyond database systems and the internally sourced data that formed the early foundations of business computing and BI. Context becomes key - Now...Business unIntelligence.
Wikipedia: Definition Data Governance. MIKE2.0. EIM Institute. Data Governance Institute (US)