
Database Revolution; Future of Information Publishing. Extract, transform, load. In computing, extract, transform, and load (ETL) refers to a process in database usage and especially in data warehousing that: Extracts data from outside sourcesTransforms it to fit operational needs, which can include quality levelsLoads it into the end target (database, more specifically, operational data store, data mart, or data warehouse) ETL systems are commonly used to integrate data from multiple applications, typically developed and supported by different vendors or hosted on separate computer hardware.
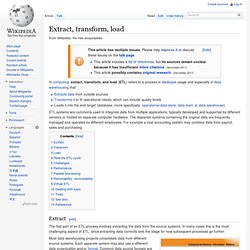
The disparate systems containing the original data are frequently managed and operated by different employees. For example a cost accounting system may combine data from payroll, sales and purchasing. Extract[edit] The first part of an ETL process involves extracting the data from the source systems. ETL Architecture Pattern Most data warehousing projects consolidate data from different source systems. Neo4j. 0830 - Cypher and Neo4j.
Neo4j Internals: File Storage. NOTE: This post is quite outdated, stuff has changed since i wrote this.
While you can somewhat safely ignore the alterations for increased address space of entities, the Property store has changed in a fundamental way. Please find the new implementation here. Ah, the physical layer! Storing bits and bytes on spinning metal, away from the security and comfort of objects and high-level abstractions. This is the realization of any database system, the sole purpose for which it is build. Which files again? By now you should be aware that your graph lives in a bunch of files under the directory which you instructed your instance to store them. Recycling Ids I will tell a lie now but I have to start somewhere. Neo4j open source nosql graph database. MongoDB. InfiniteGraph. Atomic Wiki. Higher-order functions are probably the most notable addition to the XQuery language in version 3.0 of the specification .

While it may take some time to understand their full impact, higher-order functions certainly open a wide range of new possibilities, and are a key feature in all functional languages. As of April 2012, eXist-db completely supports higher-order functions, including features like inline functions, closures and partial function application. This article will quickly walk through each feature before we put them all together in a practical example. Using A Graph Database To Power The “Web of Things” Www.iacis.org/iis/2009_iis/pdf/p2009_1301.pdf. AllegroGraph News August 2011. AllegroGraph News.

Gremlin. Orient Technologies - Open source solutions built around the Orient DB. High-performance graph database, data deduplication and bibliographic exploration. Orient - NoSQL document database light, portable and fast. Supports ACID Tx, Indexes, asynch queries, SQL layer, clustering, etc. Graph-database.org. Object-Oriented Database (OODBMS) Virtuoso.openlinksw.com. Database Models: Hierarcical, Network, Relational, Object-Oriented, Semistructured, Associative and Context. The context data model combines features of all the above models.

It can be considered as a collection of object-oriented, network and semistructured models or as some kind of object database. In other words this is a flexible model, you can use any type of database structure depending on task. Such data model has been implemented in DBMS ConteXt. The fundamental unit of information storage of ConteXt is a CLASS. Class contains METHODS and describes OBJECT.
Unified Modeling Language. The Unified Modeling Language (UML) is a general-purpose modeling language in the field of software engineering, which is designed to provide a standard way to visualize the design of a system.[1] It was created and developed by Grady Booch, Ivar Jacobson and James Rumbaugh at Rational Software during 1994–95 with further development led by them through 1996.[1] In 1997 it was adopted as a standard by the Object Management Group (OMG), and has been managed by this organization ever since.
In 2000 the Unified Modeling Language was also accepted by the International Organization for Standardization (ISO) as an approved ISO standard. Since then it has been periodically revised to cover the latest revision of UML.[2] Overview[edit] Associative model of data. Entity-relationship model. An entity–relationship diagram using Chen's notation In software engineering, an entity–relationship model (ER model) is a data model for describing the data or information aspects of a business domain or its process requirements, in an abstract way that lends itself to ultimately being implemented in a database such as a relational database.
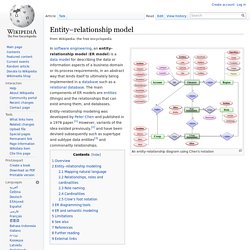
The main components of ER models are entities (things) and the relationships that can exist among them, and databases. Entity–relationship modeling was developed by Peter Chen and published in a 1976 paper.[1] However, variants of the idea existed previously,[2] and have been devised subsequently such as supertype and subtype data entities[3] and commonality relationships. Overview[edit] Jeremy Zawodny's blog. I found myself reading NoSQL is a Premature Optimization a few minutes ago and threw up in my mouth a little.

That article is so far off base that I’m not even sure where to start, so I guess I’ll go in order. In fact, I would argue that starting with NoSQL because you think you might someday have enough traffic and scale to warrant it is a premature optimization, and as such, should be avoided by smaller and even medium sized organizations. You will have plenty of time to switch to NoSQL as and if it becomes helpful. Until that time, NoSQL is an expensive distraction you don’t need. Uhm… WHAT?!
I’ve spent more than a few years using MySQL and have been using some NoSQL systems for the last year or so in a fairly busy environment. NoSQL exists for a reason–because they ARE useful to a lot of people. The Apache Cassandra Project. YAGO-NAGA - D5: Databases and Information Systems (Max-Planck-Institut für Informatik) Thomas Neumann: D5: Databases and Information Systems (Max-Planck-Institut für Informatik)