
RAID (informatique) Un article de Wikipédia, l'encyclopédie libre.
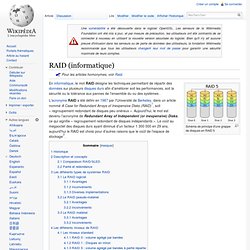
Pour les articles homonymes, voir Raid. Schéma de principe d'une grappe de disques en RAID 5 La technologie RAID a été élaborée par un groupe de chercheurs de l'université de Californie à Berkeley en 1987. Ces derniers étudièrent la possibilité de faire reconnaître deux disques durs ou plus comme une seule entité par le système. Ils obtinrent pour résultat un système de stockage aux performances bien meilleures que celles des systèmes à disque dur unique, mais doté d'une très mauvaise fiabilité. En 1988, les différents RAID, de type 1 à 5, étaient formellement définis par David Patterson, Garth Gibson et Randy Katz dans la publication intitulée « A Case for Redundant Arrays of Inexpensive Disks (RAID)[4] ».
En effet, dans une architecture de type SLED, la bonne conservation des données est dépendante de la moindre défaillance du disque dur. Le système de redondance le plus simple et le plus largement utilisé est le calcul de parité. Heartbeat (programme) Un article de Wikipédia, l'encyclopédie libre.
Heartbeat écoute les battements de cœur - des signaux émis par les services d'une grappe de serveurs lorsqu'ils sont opérationnels. Il exécute des scripts d'initialisations lorsqu'une machine tombe (plus d'entente du battement de cœur) ou est à nouveau disponible. Il permet aussi de changer d'adresse IP entre les deux machines à l'aide de mécanismes ARP avancés.
Heartbeat fonctionne à partir de deux machines et peut être mis en place pour des architectures réseaux plus complexes. Les « battements de cœurs » peuvent être prévus de différentes façons : Site officiel. Tolérance aux pannes. Un article de Wikipédia, l'encyclopédie libre.
La tolérance aux pannes (on dit également « insensibilité aux pannes ») désigne une méthode de conception permettant à un système de continuer à fonctionner, éventuellement de manière réduite (on dit aussi en « mode dégradé »), au lieu de tomber complètement en panne, lorsque l'un de ses composants ne fonctionne plus correctement. L'expression est employée couramment pour les systèmes informatiques étudiés de façon à rester plus ou moins opérationnels en cas de panne partielle, c'est-à-dire éventuellement avec une réduction du débit ou une augmentation du temps de réponse.
En d'autres termes, le système ne s'arrête pas de fonctionner, qu'il y ait défaillance matérielle ou défaillance logicielle. Un exemple en dehors de l'informatique est celui du véhicule à moteur conçu pour être toujours en état de rouler même si l'un de ses pneus est crevé. Critères de tolérance aux pannes[modifier | modifier le code] La disponibilité correspond à.
Spanning tree protocol. Le problème[modifier | modifier le code] Les réseaux commutés de type Ethernet doivent avoir un chemin unique entre deux points, cela s'appelle une topologie sans boucle.

En effet, la présence de boucle génère des tempêtes de diffusion qui paralysent le réseau : tous les liens sont saturés de trames de diffusion qui tournent en rond dans les boucles et les tables d'apprentissage des commutateurs (switch) deviennent instables. Une solution serait de ne pas tirer les câbles en surnombre de manière à ne pas avoir de boucles dans le réseau. Néanmoins, un bon réseau doit aussi offrir de la redondance pour proposer un chemin alternatif en cas de panne d'une liaison ou d'un commutateur (switch).
L'algorithme de « spanning tree minimum » garantit l'unicité du chemin entre deux points du réseau tout en n'interdisant pas les câbles en surnombre. Mode de fonctionnement[modifier | modifier le code] Réseau d'exemple représentant le fonctionnement de STP 1. 6. Il existe trois types de BPDU :