
Hadoop Internals. Big Data Benchmark. Click Here for the previous version of the benchmark Introduction Several analytic frameworks have been announced in the last year.
Big Data Benchmark. Migrating to MapReduce 2 on YARN (For Operators) Cloudera Manager lets you add a YARN service in the same way you would add any other Cloudera Manager-managed service.

In Apache Hadoop 2, YARN and MapReduce 2 (MR2) are long-needed upgrades for scheduling, resource management, and execution in Hadoop. At their core, the improvements separate cluster resource management capabilities from MapReduce-specific logic. They enable Hadoop to share resources dynamically between MapReduce and other parallel processing frameworks, such as Cloudera Impala; allow more sensible and finer-grained resource configuration for better cluster utilization; and permit Hadoop to scale to accommodate more and larger jobs.
In this post, operators of Cloudera’s distribution of Hadoop and related projects (CDH) who want to upgrade their existing setups to run MR2 on top of YARN will get a guide to the architectural and user-facing differences between MR1 and MR2. (MR2 is the default processing framework in CDH 5, although MR1 will continue to be supported.)
Data warehouse augmentation, Part 1: Big data and data warehouse augmentation. Develop and deploy your nextapp on the IBM Bluemixcloud platform.

Start building for free This article describes the big data technologies, which are based on Hadoop, that can be implemented to augment existing data warehouses. Traditional data warehouses are built primarily on relational databases that analyze data from the perspective of business processes. Part 1 of this series describes the current state of the data warehouse, its landscape, technology, and architecture. Introduction to YARN. Develop and deploy your nextapp on the IBM Bluemixcloud platform.
Start building for free Introduction Apache Hadoop 2.0 includes YARN, which separates the resource management and processing components. The YARN-based architecture is not constrained to MapReduce. This article describes YARN and its advantages over the previous distributed processing layer in Hadoop. Big data architecture and patterns, Part 1: Introduction to big data classification and architecture. Overview Big data can be stored, acquired, processed, and analyzed in many ways.
Every big data source has different characteristics, including the frequency, volume, velocity, type, and veracity of the data. When big data is processed and stored, additional dimensions come into play, such as governance, security, and policies. Smart Data Access with HADOOP HIVE “SAP HANA smart data access enables remote data to be accessed as if they are local tables in SAP HANA, without copying the data into SAP HANA.
Not only does this capability provide operational and cost benefits, but most importantly it supports the development and deployment of the next generation of analytical applications which require the ability to access, synthesize and integrate data from multiple systems in real-time regardless of where the data is located or what systems are generating it.” Reference: Section 2.4.2.
Presto: Interacting with petabytes of data at Facebook. Parquet: Columnar Storage for Hadoop. Optimizing Hive Queries. OpenTSDB - A Distributed, Scalable Monitoring System. Innovations in Apache Hadoop MapReduce Pig Hive for Improving Query... Cloudera Impala: A Modern SQL Engine for Apache Hadoop. Phoenix - SQL over HBase. Distributed SQL Query Engine for Big Data.
How Hadoop Works? HDFS case study. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
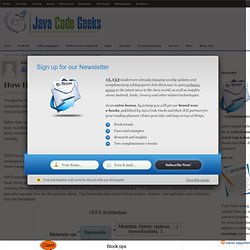
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. The Hadoop library contains two major components HDFS and MapReduce, in this post we will go inside each HDFS part and discover how it works internally.
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. The Hadoop ecosystem: the (welcome) elephant in the room (infographic) To say Hadoop has become really big business would be to understate the case.

At a broad level, it’s the focal point of a immense big data movement, but Hadoop itself is now a software and services market of its very own. In this graphic, we aim to map out the current ecosystem of Hadoop software and services — application and infrastructure software, as well as open source projects — and where those products fall in terms of use cases and delivery model. Click on a company name for more information about how they are using this technology. A couple of points about the methodology might be valuable: The first is that these are products and projects that are built with Hadoop in mind and that aim to either extend its utility in some way or expose its core functions in a new manner. This is the second installment of our four-part series on the past, present and future of Hadoop.
Hama - a general BSP framework on top of Hadoop. Apache Spark™ - Lightning-Fast Cluster Computing. Comparing Pattern Mining on a Billion Records with HP Vertica and Hadoop. Pattern mining can help analysts discover hidden structures in data.
Pattern mining has many applications—from retail and marketing to security management. For example, from a supermarket data set, you may be able to predict whether customers who buy Lay’s potato chips are likely to buy a certain brand of beer. Similarly, from network log data, you may determine groups of Web sites that are visited together or perform event analysis for security enforcement.
In this blog post, we will show you how the HP Vertica Analytics Platform can efficiently find frequent patterns in very large data sets. Apache Hadoop 2.5.0 - Hadoop in Secure Mode. Common Configurations In order to turn on RPC authentication in hadoop, set the value of hadoop.security.authentication property to "kerberos", and set security related settings listed below appropriately.

The following properties should be in the core-site.xml of all the nodes in the cluster. Configuration for WebAppProxy The WebAppProxy provides a proxy between the web applications exported by an application and an end user. If security is enabled it will warn users before accessing a potentially unsafe web application. LinuxContainerExecutor A ContainerExecutor used by YARN framework which define how any container launched and controlled. The following are the available in Hadoop YARN: To build the LinuxContainerExecutor executable run: $ mvn package -Dcontainer-executor.conf.dir=/etc/hadoop/ The path passed in -Dcontainer-executor.conf.dir should be the path on the cluster nodes where a configuration file for the setuid executable should be located.
Conf/container-executor.cfg. Distributed SQL Query Engine for Big Data. Index - Apache ZooKeeper. Skip to end of metadataGo to start of metadata ZooKeeper: Because coordinating distributed systems is a Zoo ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Talend. Hadoop, MapReduce and processing large Twitter datasets for fun and profit. This fall I just enrolled back to complete my PhD at the School of Journalism and Mass Communications (SJMC) at the University of Wisconsin-Madison.
As part of my activities, I’ve been attending the sessions of the Social Media and Democracy research group at SJMC, a great collaborative effort to further research in Social Media and how it’s used in political communications. As part of a series of upcoming research projects on a HUGE Twitter dataset collected SMAD during the US 2012 presidential election, we’ve been brushing up on Python, Hadoop and MapReduce. I’m very excited about this opportunity, as big data analysis seems to be coming of age and gaining traction on in several areas of communication research.
As part of our training, Alex Hanna, a sociology PhD student at UW-Madison, put together an excellent series of workshops on Twitter (or, as he’s aptly named them, “Tworkshops“) to get the whole SMAD team started in the art of big data analysis. Be Sociable, Share! RealTime Hadoop Example - Analyse Tweets using Flume, Hadoop and Hive.
Think Big » Technologies. Presentations - Apache Hive. Skip to end of metadataGo to start of metadata A list of presentations mainly focused on Hive November 2011 NYC Hive Meetup Presentations. Analyzing Twitter Data with Apache Hadoop. Social media has gained immense popularity with marketing teams, and Twitter is an effective tool for a company to get people excited about its products. Twitter makes it easy to engage users and communicate directly with them, and in turn, users can provide word-of-mouth marketing for companies by discussing the products. Given limited resources, and knowing we may not be able to talk to everyone we want to target directly, marketing departments can be more efficient by being selective about whom we reach out to.
Hadoop Connector — MongoDB Ecosystem 2.2.2. The MongoDB Connector for Hadoop is a plugin for Hadoop that provides the ability to use MongoDB as an input source and/or an output destination. The source code is available on github where you can find a more comprehensive readme. If you have questions please email the mongodb-user Mailing List. For any issues please file a ticket in Jira.