
CCDP Self-Study: Designing High-Availability Services > High-Availability Features and Options. After completing this chapter, you will be able to.

Determining Your High Availability Requirements. This framework enables the business to define service level agreements (SLAs) in terms of high availability for critical aspects of its business.
For example, it can categorize its business processes into several high availability tiers: The next step for the business is to evaluate the capabilities of the various high availability systems and technologies, and choose the ones that meet its SLA requirements, within the guidelines as dictated by business performance issues, budgetary constraints, and anticipated business growth. 3.3.1 High Availability Systems Capabilities A broad range of high availability and business continuity solutions exists today.
As the sophistication and scope of these systems increase, they make more of the IT infrastructure, such as the data storage, server, network, applications, and facilities, highly available. Maintaining synchronized remote data centers is an example where redundancy is built along the entire system's infrastructure. Link aggregation. Link Aggregation between a switch and a server Other umbrella terms used to describe the method include port trunking,[1] link bundling,[2] Ethernet/network/NIC bonding,[1], channel bonding or NIC teaming.
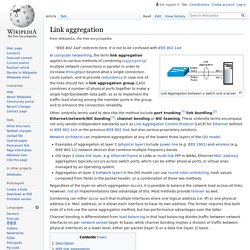
These umbrella terms encompass not only vendor-independent standards such as Link Aggregation Control Protocol (LACP) for Ethernet defined in IEEE 802.1AX or the previous IEEE 802.3ad, but also various proprietary solutions. Network architects can implement aggregation at any of the lowest three layers of the OSI model. Examples of aggregation at layer 1 (physical layer) include power line (e.g. IEEE 1901) and wireless (e.g. Regardless of the layer on which aggregation occurs, it is possible to balance the network load across all links. Combining can either occur such that multiple interfaces share one logical address (i.e. Description[edit] Continuous Operations and High Availability. Overview The Cisco Nexus 7000 platform is modular in its design, with an emphasis on redundant critical components throughout all of its subsystems.

A highly modular and compartmentalized approach to systems design is applied to all facets of the platform, spanning across the physical, environmental, power, and system software aspects of its architecture. Additionally, a distinct functional separation between control plane and forwarding data plane is emphasized in its design in order to allow continuous operation and zero service disruption during planned or unplanned control-plane events or failures. Microsoft Virtual Academy – Learn Failover Clustering & Hyper-V - Clustering and High-Availability. Would you like to learn how to deploy, manage, and optimize a Windows Server 2012 R2 failover cluster?

The Microsoft Virtual Academy is a free training website for IT Pros with over 2.7 million students. This technical course can teach you everything you want to know about Failover Clustering and Hyper-V high-availability and disaster recovery, and you don’t even need prior clustering experience! Start today: Evaluating High-Availability (HA) vs. Fault Tolerant (FT) Solutions - Clustering and High-Availability. When evaluating how to increase availability and reduce downtime for your deployments, solutions can commonly be categorized as either a 'High Availability' solution or a 'Fault Tolerant' solution.

In this blog I thought I would take a moment to discuss pros and cons of each. High availability solutions traditionally consist of a set of loosely coupled servers which have failover capabilities. Each system is independent and self-contained, yet the servers are health monitoring each other and in the event of a failure, applications will be restarted on a different server in the pool of the cluster. The myth of five nines – Why high availability is overrated. Join 12,000 others and follow Sean Hull on Twitter @hullsean.

In the Internet world 24×7 has become the de facto standard. Websites must be always on, available 24 hours a day, 365 days a year. In our pursuit of perfection, performance is being measured down to three decimal places, that is being up 99.999% of the time; in short, five-nines Just like a mantra, when repeated enough it becomes second nature and we don’t give the idea a second thought. We don’t stop to consider that while it may be generally a good thing to have, is five-nines necessary and is it realistic for the business? Also: How to hire a developer that doesn’t suck In my dealings with small businesses, I’ve found that the ones that have been around longer, and with more seasoned managers tend to take a more flexible and pragmatic view of the five-nines standard.
Of course the type of business you run might well inform your policy here. Related: Why generalists are better at scaling the web Complex architecture downtime. Create a high availability architecture and strategy for SharePoint 2013. Availability is measured in relation to being operational 100% of the time, or never down.
The common measure of availability in the IT world is expressed as a number of 9s, ranging from one nine (90%) to five nine (99.999%), the ideal. The number of nines measure is the percentage of time that a given system is running, functioning, and available to users. The availability percentage is calculated using the formula x = (n - y) * 100/n. Create a high availability architecture and strategy for SharePoint 2013.