
Raw 1.0 - Basic Tutorial. Observability at Twitter. As Twitter has moved from a monolithic to a distributed architecture, our scalability has increased dramatically.
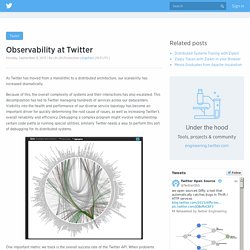
Because of this, the overall complexity of systems and their interactions has also escalated. This decomposition has led to Twitter managing hundreds of services across our datacenters. Visibility into the health and performance of our diverse service topology has become an important driver for quickly determining the root cause of issues, as well as increasing Twitter’s overall reliability and efficiency.
Debugging a complex program might involve instrumenting certain code paths or running special utilities; similarly Twitter needs a way to perform this sort of debugging for its distributed systems. One important metric we track is the overall success rate of the Twitter API. Welcome to Madoko. Spring Cloud Config. Features Spring Cloud Config Server features: HTTP, resource-based API for external configuration (name-value pairs, or equivalent YAML content)Encrypt and decrypt property values (symmetric or asymmetric)Embeddable easily in a Spring Boot application using @EnableConfigServer Config Client features (for Spring applications): Bind to the Config Server and initialize Spring Environment with remote property sourcesEncrypt and decrypt property values (symmetric or asymmetric) Quick Start As long as Spring Boot Actuator and Spring Config Client are on the classpath any Spring Boot application will try to contact a config server on (the default value of spring.cloud.config.uri):
Fast, Scalable Machine Learning Platform. Tachyon Overview - Tachyon 0.7.1 Documentation. Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce.

It achieves high performance by leveraging lineage information and using memory aggressively. Tachyon caches working set files in memory, thereby avoiding going to disk to load datasets that are frequently read. This enables different jobs/queries and frameworks to access cached files at memory speed. Tachyon is Hadoop compatible. Existing Spark and MapReduce programs can run on top of it without any code change. Standard C++ Datavisualization.ch Selected Tools. Berkeley DB: Architecture - Karan Sikka. In my quest to learn more about how databases work, I started with Berkeley DB for one reason: simplicity.
It doesn’t parse SQL, it doesn’t create a query plan, it doesn’t have a client/server architecture. It’s just a key-value store that you #include in your code. Intuitively it seems like it could be a building block in constructing a full blown relational database server. Designing a GC in Rust - In Pursuit of Laziness. For a while I’ve been working on a garbage collector for Rust with Michael Layzell.

I thought this would be a good time to talk of our design and progress so far. “Wait”, you ask, “why does Rust need a garbage collector”? Rust is supposed to work without a GC, that’s one of its main selling points! True. Calculus on Computational Graphs: Backpropagation. Posted on August 31, 2015 Introduction Backpropagation is the key algorithm that makes training deep models computationally tractable.

For modern neural networks, it can make training with gradient descent as much as ten million times faster, relative to a naive implementation. That’s the difference between a model taking a week to train and taking 200,000 years. Beyond its use in deep learning, backpropagation is a powerful computational tool in many other areas, ranging from weather forecasting to analyzing numerical stability – it just goes by different names. Fundamentally, it’s a technique for calculating derivatives quickly. Computational Graphs. Select a Language. Help What is repl.it?
It is an online environment for interactively exploring programming languages. The name comes from the read-eval-print loop, the interactive toplevel used by languages like Lisp and Python. How do I start? Once you have selected a language, start by typing an expression into the console on the right side of the screen and pressing Enter. Free Online Introduction to LaTeX - Part 1: The Basics - Overleaf. Welcome to the first part of our free online course to help you learn LaTeX.
If you have never used LaTeX before, or if it has been a while and you would like a refresher, this is the place to start. This course will get you writing LaTeX right away with interactive exercises that can be completed online, so you don't have to download and install LaTeX on your own computer. In this part of the course, we'll take you through the basics of how LaTeX works, explain how to get started, and go through lots of examples. Core LaTeX concepts, such as commands, environments, and packages, are introduced as they arise. In particular, we'll cover: Dell-oss/Doradus.
Distributed Consensus Reloaded: Apache ZooKeeper and Replication in Apache Kafka. This post was jointly written by Neha Narkhede, co-creator of Apache Kafka, and Flavio Junqueira, co-creator of Apache ZooKeeper.
Many distributed systems that we build and use currently rely on dependencies like Apache ZooKeeper, Consul, etcd, or even a homebrewed version based on Raft [1]. Although these systems vary on the features they expose, the core is replicated and solves a fundamental problem that virtually any distributed system must solve: agreement. Processes in a distributed system need to agree on a master, on the members of a group, on configuration, on the owner of a lock, and on when to cross a barrier. These are all problems commonly found in the design of distributed systems, and the approach of adopting one of these dependencies has been successful because these systems fundamentally solve the distributed consensus problem [2].
Loading Data Into MemSQL. Now that MemSQL is up and running, we’ll cover how to load data into the database.
This guide covers various ways of loading data into the system. We recommend trying option 1, and if that is not sufficient, trying option 2 then option 3. Option 1: Loading Data stored in a file¶ MemSQL supports standard SQL loading constructs. For instance, after creating tbl_name, run: Placement New, Memory Dumps, and Alignment - Morning Musings.
Generally, in C++ there are three places you can store your data: On the stack (local variables)On the heap (new / delete)In the static data section (static variables) Normally, when using the heap, you would use the following command: Top 10 Practices for Effective DevOps. Stupid Gopher Tricks. GolangUK 21 August 2015 This talk This talk is about things you might not know about Go. Some of this stuff you can add to your Go vocabulary. PythonTips/Best Python Resources for Beginners and Professionals.MD at master · yasoob/PythonTips. Developing Backbone.js Applications - By Addy Osmani (@addyosmani) Available free for open-source reading below or for purchase via the O'Reilly store. Pull requests and comments always welcome.
Prelude Not so long ago, “data-rich web application” was an oxymoron. Today, these applications are everywhere and you need to know how to build them. Traditionally, web applications left the heavy-lifting of data to servers that pushed HTML to the browser in complete page loads. Targeting Monkey. We need a bigger plan! Do you need more than that? Get in touch for a custom plan. We are an agency! We offer volume discount and reseller deals. Just get in touch. -> To get in touch, send an email to team@targetingninja.com. Performance Engineering at Realm: How we optimized binary search. Performance Engineering at Realm At Realm, we’re always looking for ways to optimize for speed. This is the story of how we developed our own fast binary search function, with an execution time on average 24% faster than the C++ STL.
Why Binary Search? Realm stores data in binary tree structures. For example, suppose Realm was holding objects with the following IDs in a linked list: If you wanted to find the object with ID equaled to 14 then this would require 5 operations or rather O(n) complexity. Metrics 2.0: an emerging set of standards around metrics. FlatBuffers: FlatBuffer Internals. This section is entirely optional for the use of FlatBuffers. In normal usage, you should never need the information contained herein. If you're interested however, it should give you more of an appreciation of why FlatBuffers is both efficient and convenient. Advanced Git Log - Filtering the commit history. The purpose of any version control system is to record changes to your code. This gives you the power to go back into your project history to see who contributed what, figure out where bugs were introduced, and revert problematic changes. But, having all of this history available is useless if you don’t know how to navigate it.
That’s where the git log command comes in. By now, you should already know the basic git log command for displaying commits. But, you can alter this output by passing many different parameters to git log. The advanced features of git log can be split into two categories: formatting how each commit is displayed, and filtering which commits are included in the output. Draftin. Testing in Go. Solving multi-core Python.
[JavaSpecialists 230] - String Substring. The Java Specialists' Newsletter Issue 230. Code as Craft, Etsy's Engineering Blog. Welcome to CS 61AS! Orion Project Homepage. Open Source Container Cluster Orchestration: How did the Quake demo from DockerCon Work? Shortly after its release in 2013, Docker became a very popular open source container management tool for Linux. Docker has a rich set of commands to control the execution of a container. Commands such as start, stop, restart, kill, pause, and unpause. However, what is still missing is the ability to Checkpoint and Restore (C/R) a container natively via Docker itself.
We’ve been actively working with upstream and community developers to add support in Docker for native C/R and hope that checkpoint and restore commands will be introduced in Docker 1.8. As of this writing, it’s possible to C/R a container externally because this functionality was recently merged in libcontainer. Off-CPU Analysis. Soundcloud/cando. Soundcloud/pipeline-generator. Kibana 4 Tutorial – Part 1: Introduction » Tim Roes. This tutorial is up to date with Kibana 4.0.1. Kibana 4 is the new version of Kibana, a web frontend to analyze data held in an elasticsearch cluster, with lots of changes compared to the prior Kibana 3 version. Thoughts on Time-series Databases. Rhuss/aji. Rhuss/aji. Pipefy - The easiest way to manage your business processes and routines. Coding Projects for Early Coders. Wine with chicken - Wine Pairing for chicken. Jolokia + Highcharts = JMX for human beings. Java Management Extensions (JMX) is a well established, but not widespread technology allowing to monitor and manage every JVM.
It provides tons of useful information, like CPU, thread and memory monitoring. Also every application can register its own metrics and operations in so called MBeanServer. Several libraries take advantage of JMX: Hibernate, EhCache and Logback and servers like Tomcat or Mule ESB, to name a few. This way one can monitor ORM performance, HTTP worker threads utilization, but also change logging levels, flush caches, etc. GitHub forking has one big flaw - zbowling blag. Github is amazing.
Fast Approximate Logarithms, Part I: The Basics. Performance profiling of some of the eBay code base showed the logarithm (log) function to be consuming more CPU than expected. Bite-sized learning for Product Managers. Portworx. ZenHub 2.0 : Project management, evolved. Watchdog — watchdog 0.8.2 documentation. HIPERFIT. Bootcards documentation. Alebcay/awesome-shell. Jlevy/the-art-of-command-line. Jakubroztocil/httpie. Kiji Project. Security Master data model (includes OTC trade data) - Latest Version - OpenGamma Documentation.
How to model data in Cassandra for last 100 events for a customer. An Advanced Cassandra Data Modeling Guide - Open Source. Cassandra week. ØMQ - The Guide - ØMQ - The Guide. Simple C++11 metaprogramming. S Guides. S Guide to Network Programming. A fork() Primer. GC Tuning Confessions Of A Performance Engineer. Using temporal tables in DB2 10 for z/OS and DB2 11 for z/OS. Accounting for Developers 101 - Google Docs. RocketChat/Rocket.Chat. 1000+ Beginner Programming Projects (x-post /r/programming) : learnprogramming. Martyr2's Mega Project Ideas List! - Share Your Project. Zyantific/zyan-disassembler-engine. Accounting for Developers 101 - Google Docs. Elusive Algorithms – Parallel Scan. FpML® Schema LiveSearch (Beta)
Index. MemSQL Resources - Fastest SQL Database, MemSQL. Javaslang. Javaslang. Datomic - Home. Lock-Free Data Structures. Exploring Queues. Getting started with Flowthings - The Python Chat Example - Tutorials - flowthings.io. Work-Bench Blog - The State of the Container – April. DNSMasq Configuration. Call me maybe: Aerospike. Where Rust Really Shines - In Pursuit of Laziness. Seaborn: statistical data visualization — seaborn 0.5.1 documentation. Death To C. How to explain the value of replicated, shared ledgers from first principles. Settlement-Matrix20040701.pdf. Zero-Overhead Metaprogramming: Reflection and Metaobject Protocols Fast and without Compromises. Tsung.
Product Hunt Predicts the Tech Hits of 2016. Jsonnet - The Data Templating Language. Writing Bug-Free C Code. 40 Key Computer Science Concepts Explained In Layman’s Terms. An Advanced Cassandra Data Modeling Guide - Open Source. Advanced Time Series with Cassandra. Cassandra Data Modeling Best Practices, Part 1.