
PyWordNet. Thesaurus and taxonomy library for python. Www.nltk.org/book/ch09.html. Natural languages have an extensive range of grammatical constructions which are hard to handle with the simple methods described in 8.

In order to gain more flexibility, we change our treatment of grammatical categories like S, NP and V. In place of atomic labels, we decompose them into structures like dictionaries, where features can take on a range of values. Along the way, we will cover more topics in English syntax, including phenomena such as agreement, subcategorization, and unbounded dependency constructions. 9.1 Grammatical Features. Data. Sentence Diagram. Reed-Kellogg Diagrammer Help. What is it good for?

The Reed-Kellogg Diagrammer automatically analyzes and diagrams a sentence for you. It draws diagrams in traditional form. Small World of Words Project. Welcome to the small world of words project!
Last modified: April 16, 2014 Voor Nederlandstalige informatie, klik hier The small world of words project is a large-scale scientific study that aims to build a map of the human lexicon in the major languages of the world and make this information widely available. In contrast to a thesaurus or dictionary, this lexicon provides insight into what words and what part of their meaning are central in the human mind.
This way it enables psychologists, linguists, neuroscientists and others to test new theories about how we represent and process language. History through the president’s words. Introducing the State of the Union Machine. Tomorrow night, President Barack Obama will give the annual State of the Union address to a joint session of Congress.
Today, you can generate your own random speech with Sunlight's new State of the Union Machine that is modeled on the language in different presidents' previous addresses. The project generates random text so the speeches will likely be a mix of eloquent presidential prose and uncomfortable executive dissonance. To generate a new speech just adjust the sliders to alter the weight given to each president.
We built the State of the Union Machine using language modeling to randomly generate text based on different presidents' previous speeches. Visualization of Narrative. Visualization | Tools and Inspiration | Press Visualization of Narrative Structure Can books be summarized through their emotional trajectory and character relationships?

Can a graphic representation of a book provide an at-a-glance impression and an invitation to explore the details? We visualized character interactions and relative emotional content for three very different books: a haunting memory play, a metaphysical mood piece, and a children's fantasy classic. A dynamic graph of character relationships displays the evolution of connections between characters throughout the book. EuroVoc. Linux and Open source Linux Terminal: How to do fuzzy search with tre-agrep. Probably everyone that use a terminal know the command grep, from its man page: grep searches the named input FILEs (or standard input if no files are named, or if a single hyphen-minus (-) is given as file name) for lines containing a match to the given PATTERN.
By default, grep prints the matching lines. So this is the best tool to search in big file for a specific pattern, or a specific process in the complete list of running processes, but it has a small limit, it searches for the exact string that you ask, and sometime it could be useful to do an “approximate” or “fuzzy” search. TRE — The free and portable approximate regex matching library. You can find it here.
It’s been there a while, but probably no-one has noticed: The repo has been migrated from the old repo in Darcs. Pull requests are welcome. As you may already know, the Darcs repository and the mailing list as well as the archive are down. How Google Converted Language Translation Into a Problem of Vector Space Mathematics. Computer science is changing the nature of the translation of words and sentences from one language to another.
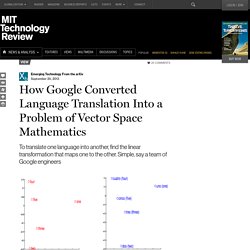
Anybody who has tried BabelFish or Google Translate will know that they provide useful translation services but ones that are far from perfect. The basic idea is to compare a corpus of words in one language with the same corpus of words translated into another. (85) neologism-tracker. Neologism - Easy RDFS Vocabulary Publishing. Search results for - support. Autocorrect: How does it work? Do we need it? Autocorrect is almost as old as personal computers.
Even some of the earliest word processors had a spellcheck feature that suggested alternative words if a word you typed did not appear in its internal dictionary. Certainly, today, autocorrect has a come a long way since the Cupertino effect. What’s the Cupertino effect? Well, in its early days, word processors would replace the word “cooperation” with “Cupertino” (the city in Northern California where Apple and other computer companies are headquartered). This spelling suggestion made its way to many documents published by the United Nations, NATO, and other official bodies, so the Cupertino effect is any inappropriate suggestion or autocorrection made by a spellchecker. Natural Language Processing Tools. Seeking Lovecraft, Part 1: An introduction to NLP and the Treat Gem. We just started Unknowable Horror LLC.
Our plan is sift through the vast ocean of bytes that is the internet in order to find the next H.P. Lovecraft so that we can make a fortune selling masterful cosmic horror. Alternatively, if we can’t find the next H.P. Verbs.colorado.edu/~mpalmer/Ling7800/complexsem4.pdf. Seeking Lovecraft, Part 1: An introduction to NLP and the Treat Gem. Natural Language Processing Tools. NLP - Natural Langauge Processing - Centre Lucien Tesnière - Multicodict Project. About WordNet - WordNet - About WordNet. Nlp - English dictionary as txt or xml file with support of synonyms. L'intelligence économique en quelques clics. Souvent réducteurs, parfois caricaturaux, les profils de consommateurs identifiés par les études de marché n’en demeurent pas moins intéressants.
Ne serait-ce que pour explorer et analyser des tendances de comportements. Le livre blanc publié par Aimia sur les utilisateurs américains des médias sociaux (« Identifier, comprendre et influencer les utilisateurs des médias sociaux ») vaut le coup d’œil surtout parce que les tendances observées outre-atlantique préfigurent souvent ce qui se passe ailleurs, plus tard. Aimia a d’abord conçu un modèle censé représenter l’usage des médias sociaux selon 2 critères : le niveau de participation et le niveau d’exposition de l’internaute. Opinion mining et sentiment analysis: méthodes et outils. Opinion mining et Sentiment analysis. Sentiment analysis. Sentiment analysis (also known as opinion mining) refers to the use of natural language processing, text analysis and computational linguistics to identify and extract subjective information in source materials. Generally speaking, sentiment analysis aims to determine the attitude of a speaker or a writer with respect to some topic or the overall contextual polarity of a document.
The attitude may be his or her judgment or evaluation (see appraisal theory), affective state (that is to say, the emotional state of the author when writing), or the intended emotional communication (that is to say, the emotional effect the author wishes to have on the reader). Www.cs.cornell.edu/home/llee/omsa/omsa-published. Opinion mining and sentiment analysis (survey) Bo Pang and Lillian LeeFoundations and Trends in Information Retrieval 2(1-2), pp. 1–135, 2008. Also available as a book or e-book. Whissell’s Dictionary of Affect in Language for emotional text recognition.
Center for the Study of Emotion and Attention. ANEW Message Dear Colleague Thank you for your interest in the Affective Norms for English Words (ANEW). Nlp - Word Map for Emotions. Google Ngram Viewer. The Google Books Ngram Viewer is optimized for quick inquiries into the usage of small sets of phrases. If you're interested in performing a large scale analysis on the underlying data, you might prefer to download a portion of the corpora yourself. Or all of it, if you have the bandwidth and space.
We're happy to oblige. These datasets were generated in July 2012 (Version 2) and July 2009 (Version 1); we will update these datasets as our book scanning continues, and the updated versions will have distinct and persistent version identifiers (20120701 and 20090715 for the current sets). Ngram Viewer. NPR Puzzle: Finding Synonyms with Python and WordNet. This week’s puzzle asks: From Alan Meyer of Newberg, Ore.: Think of a common word that’s six letters long and includes a Q. Change the Q to an N, and rearrange the result to form a new word that’s a synonym of the first one.
What are the words? WordNet Interface. Nlp - Wordnet Find Synonyms. Www-nlp.stanford.edu/~htseng/synonym_coling.pdf. The linguistic clues that reveal your true Twitter identity. Saffsd/langid.py. Python - NLTK and language detection. Detecting text language with python and NLTK - Alejandro Nolla - z0mbiehunt3r. Nlp - How can I tag and chunk French text using NLTK and Python. Python - Lemmatize French text. Python 2.7 - Tokenizing in french using nltk. Text Retrieval Conference. Message Understanding Conference. Strong AI. AI-complete. In the field of artificial intelligence, the most difficult problems are informally known as AI-complete or AI-hard, implying that the difficulty of these computational problems is equivalent to that of solving the central artificial intelligence problem—making computers as intelligent as people, or strong AI.[1] To call a problem AI-complete reflects an attitude that it would not be solved by a simple specific algorithm.
AI-complete problems are hypothesised to include computer vision, natural language understanding, and dealing with unexpected circumstances while solving any real world problem.[2] Named-entity recognition. Automatic summarization. Methods[edit] Natural language processing. Natural language processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. As such, NLP is related to the area of human–computer interaction. Natural Language Processing Tools. Book/ch07.html. For any given question, it's likely that someone has written the answer down somewhere. The amount of natural language text that is available in electronic form is truly staggering, and is increasing every day.
However, the complexity of natural language can make it very difficult to access the information in that text. Book/ch07.html. Book. Projects · nltk/nltk Wiki. Installing NLTK Data — NLTK 3.0 documentation. News — NLTK 3.0 documentation. Natural Language Toolkit — NLTK 3.0 documentation. Software Tools for NLP. Clearnlp - Fast and robust NLP components implemented in Java. Clearparser - This project provides several NLP tools such as a dependency parser, a semantic role labeler, a penn-to-dependency converter, a prop-to-dependency converter, and a morphological analyzer. All tools are written in Java and developed by the Co. Natural Language Toolkit — NLTK 3.0 documentation. Collection of Natural Language Processing Tools.
Software Tools for NLP. Natural Language Processing (NLP) Survey of Tools & Resources. Natural Language Processing: What are the best tools for manually annotating a text corpus with entities and relationships. Stylometry.
NLP Resources for Ruby. Correspondence analysis. Cluster analysis. Multidimensional scaling. Co-occurrence networks. Collocation. Key Word in Context. KH Coder / Discussion / Open Discussion:Italian Text on KH Coder. KH Coder. KNIME. RapidMiner. Natural Language Toolkit. OpenNLP. General Architecture for Text Engineering. Carrot2. Lucene.Net - Text Analysis. 128.206.119.157/nlp/papers/NLPTools.pdf. Free Science & Engineering software downloads. Java Open Source Text Mining Frameworks. Java text analysis libraries. Method in text-analysis: An introduction. Text mining. Text analysis, wordcount, keyword density analyzer, prominence analysis.