
NoSQL. Un article de Wikipédia, l'encyclopédie libre.
En informatique, NoSQL désigne une famille de systèmes de gestion de base de données (SGBD) qui s'écarte du paradigme classique des bases relationnelles. L'explicitation du terme la plus populaire de l'acronyme est Not only SQL (« pas seulement SQL » en anglais) même si cette interprétation peut être discutée[1]. La définition exacte de la famille des SGBD NoSQL reste sujette à débat. Le terme se rattache autant à des caractéristiques techniques qu'à une génération historique de SGBD qui a émergé à la fin des années 2000/début des années 2010[2]. D'après Pramod J. L'architecture machine en clusters induit une structure logicielle distribuée fonctionnant avec des agrégats répartis sur différents serveurs permettant des accès et modifications concurrentes mais imposant également de remettre en cause de nombreux fondements de l'architecture SGBD relationnelle traditionnelle, notamment les propriétés ACID.
Théorie[modifier | modifier le code] ACID. Set of properties (atomicity, consistency, isolation, durability) of database transactions intended to guarantee validity even in the event of errors, power failures, etc.
According to Gray and Reuter, IMS supported ACID transactions as early as 1973 (although the term ACID came later).[3] Characteristics[edit] The characteristics of these four properties as defined by Reuter and Härder are as follows: Why use a database instead of just saving your data to disk? This Q&A is part of a weekly series of posts highlighting common questions encountered by technophiles and answered by users at Stack Exchange, a free, community-powered network of 100+ Q&A sites.
Dokkat appears to think that databases are overused. "Instead of a database, I just serialize my data to JSON, saving and loading it to disk when necessary," he writes. "All the data management is made on the program itself, which is faster AND easier than using SQL queries. " MySQL Ruby tutorial. Home This is a Ruby programming tutorial for the MySQL database.

It covers the basics of MySQL programming with Ruby. It uses the mysql2 module. The examples were created and tested on Ubuntu Linux. There is a similar MySQL C API tutorial, MySQL Visual Basic tutorial, or MySQL Python tutorial on ZetCode. You may also consider to look at the MySQL tutorial, too. MongoDB. Ruby Language Center — MongoDB Ecosystem 2.2.2. The MongoDB Ruby driver is the officially supported Ruby driver for MongoDB.
It is written in pure Ruby and is optimized for simplicity. It can be used on its own, but it also serves as the basis of several object mapping libraries. The Ruby BSON implementation is packaged in a separate gem with C and Java extensions for speed depending on the runtime enviroment. For reference on the Ruby BSON gem, see BSON. Object Mappers Because MongoDB is so easy to use, the basic Ruby driver can be the best solution for many applications.
In the context of a Rails application, an Object Document Mapper provides functionality equivalent to, but distinct from, ActiveRecord. The ODM officially supported by MongoDB is Mongoid, originally written by Durran Jordan. For tutorials on Mongoid, see Mongoid. MongoMapper. High Performance at Massive Scale – Lessons learned at Facebook. Why are Facebook, Digg, and Twitter so hard to scale? Real-time social graphs (connectivity between people, places, and things).
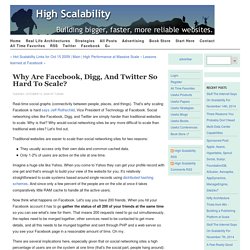
That's why scaling Facebook is hard says Jeff Rothschild, Vice President of Technology at Facebook. Social networking sites like Facebook, Digg, and Twitter are simply harder than traditional websites to scale. Do You Really Need SQL to Do It All in Cassandra? NoSQL database systems are designed for scalability.
The down side of that is a primitive key-value data model and, as the name suggest, no support for SQL. It might sound like a serious limitation – how can I “select”, “join”, “group” and “sort” the data? This post explains how all these operations can be quite naturally and efficiently implemented in one of the most famous NoSQL system – Cassandra. To understand this post you need to know the Cassandra data model. You can find a quick introduction in my previous post. DataStax Cassandra 1.2 Documentation. An index is a data structure that allows for fast, efficient lookup of data matching a given condition.
About primary indexes In relational database design, a primary key is the unique key used to identify each row in a table. A primary key index, like any index, speeds up random access to data in the table. The primary key also ensures record uniqueness, and may also control the order in which records are physically clustered, or stored by the database.
In Cassandra, the primary index for a table is the index of its row keys. Rows are assigned to nodes by the cluster-configured partitioner and the keyspace-configured replica placement strategy . With randomly partitioned row keys (the default in Cassandra), row keys are partitioned by their MD5 hash and cannot be scanned in order like traditional b-tree indexes. About secondary indexes Secondary indexes in Cassandra refer to indexes on column values (to distinguish them from the primary row key index for a table). DataStax Cassandra 1.2 Documentation. Cucumber - Making BDD fun.