
TaskForces/CommunityProjects/LinkingOpenData/SemWebClients - W3C Wiki. This page collects software components that can be used implement applications on top of the Semantic Web.
The page is not intended to list RDF toolkits that focus on local RDF processing, but toolkits that perceive the Semantic Web as a single integrated information space and help applications navigate this information space. Listings of RDF toolkits with a more local perspective are found at SemanticWebTools and Developers Guide to Semantic Web Toolkits The page is part of the LinkingOpenData community project Linked Data Browsers Tabulator.
Linked Data Mashups Revyu by Tom Heath. Linked Data Client Libraries This section lists toolkits that provide access to the Semantic Web by dereferencing resource URIs. Semantic Web Client Library The Semantic Web Client Library represents the complete Semantic Web as a single RDF graph. Crawlers and Data Extraction Tools SPARQL Endpoint Clients This section lists toolkits that support applications in querying a remote SPARQL endpoint. Papers. N400 (neuroscience) The N400 is a component of time-locked EEG signals known as event-related potentials (ERP).
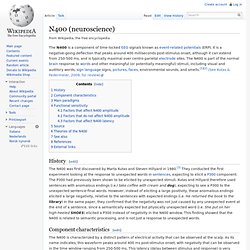
It is a negative-going deflection that peaks around 400 milliseconds post-stimulus onset, although it can extend from 250-500 ms, and is typically maximal over centro-parietal electrode sites. The N400 is part of the normal brain response to words and other meaningful (or potentially meaningful) stimuli, including visual and auditory words, sign language signs, pictures, faces, environmental sounds, and smells.[1][2] (See Kutas & Federmeier, 2009, for review) The N400 is characterized by a distinct pattern of electrical activity that can be observed at the scalp. As its name indicates, this waveform peaks around 400 ms post-stimulus onset, with negativity that can be observed in the time window ranging from 250-500 ms.
N400 (neuroscience) Distilling meaning to a number between 0 and 65,536 What is a concept? What… ScalaNLP. Updated: Convergence of synonym networks - Online Technical Discussion Groups—Wolfram Community. Take a word and find its synonyms.
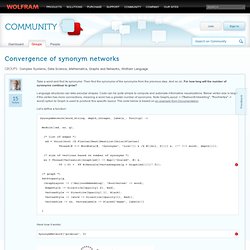
Then find the synonyms of the synonyms from the previous step. And so on. For how long will the number of synonyms continue to grow? Language structures can take peculiar shapes. Code can be quite simple to compute and automate informative visualizations. Let’s define a function: Here how it works: SynonymNetwork["promise", 3] Now as I asked earlier: will the number of synonyms continue to grow?
In[1]:= WordData["transmogrification", "Definitions"]Out[1]= {{"transmogrification", "Noun"} -> "the act of changing into a different form or appearance (especially a fantastic or grotesque one)"} In[2]:= WordData["transmogrification", "Synonyms"]Out[2]= {{"transmogrification", "Noun"} -> {}} Some words will have very trivial small finite networks (note network depth is set 20, while even 100 or greater will not change it): SynonymNetwork["chemistry", 20, Above] And of course many words will have networks that grow very fast.
Welcome to DISSECT! — DISSECT 0.1.0 documentation. GettingStarted · fozziethebeat/S-Space Wiki. Getting Started Introduction The S-Space package is a software library and suite of tools for building semantic spaces.
Semantics space algorithms capture the statistical regularities of words in a text corpora and map each word to a high-dimensional vector that represents the semantics. Language & System Documentation Center. Transforming text into knowledge. Lexalytics. API. Fully featured, in 6 languages Semantria is built upon leading enterprise Text and Analytics technologies.
Our clients benefit from years of R&D, field testing and algorithmic tweaking. All features are available in six different languages: English, French, Portuguese, Spanish, German and Mandarin. We also have Italian, Japanese and Korean in the works. Fast. The Semantria API is designed with performance in mind. Regularly submerged with millions of calls, the Semantria Cloud is well monitored and scales automatically to take the huge number of requests our clients throw at it! Try to overload it. Distributed & Scalable Our API is designed to support every possible integration scenario. We also have batch processing as well as synchronous and asynchronous modes. Highly Customizable What really sets Semantria apart from other enterprise and cloud NLP engines is configurability. Semantria has more features than any other cloud API. Comprehensive SDK Human Support Team. Word & text monitoring. Statistical NLP / corpus-based computational linguistics resources.
Contents Tools: Machine Translation, POS Taggers, NP chunking, Sequence models, Parsers, Semantic Parsers/SRL, NER, Coreference, Language models, Concordances, Summarization, Other Corpora: Large collections, Particular languages, Treebanks, Discourse, WSD, Literature, Acquisition Dictionaries Lexical/morphological resources.

About - Groningen Meaning Bank - Groningen Meaning Bank. Richard Socher - Parsing Natural Scenes And Natural Language With Recursive Neural Networks. For remarks, critical comments or other thoughts on the paper.

Save what you write before you post, then type in the password, post (nothing happens), then copy the text and re-post. It's to prevent spammers. I came across this on the Facebook group "Strong Artificial Intelligence" Thank you for the source code and all the explanations.