
A collection of self-starters for nonlinear regression in R. Usually, the first step of every nonlinear regression analysis is to select the function f, which best describes the phenomenon under study.
The next step is to fit this function to the observed data, possibly by using some sort of nonlinear least squares algorithms. These algorithms are iterative, in the sense that they start from some initial values of model parameters and repeat a sequence of operations, which continuously improve the initial guesses, until the least squares solution is approximately reached. This is the main problem: we need to provide initial values for all model parameters!
It is not irrelevant; indeed, if our guesses are not close enough to least squares estimates, the algorithm may freeze during the estimation process and may not reach convergence. Unfortunately, guessing good initial values for model parameters is not always easy, especially for students and practitioners. Straight line function Among the polynomials, we should cite the straight line. Y=aekX(3) Data Science Free Books To Get Started. 脱ハンコは「極めて狭義」 DXを分類する3階層を知ってますか?:日経クロストレンド. Withコロナで社会構造が変わる中、ビジネス変革は待ったなし。
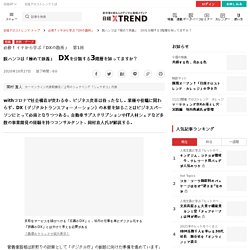
業種や役職に関わらず、DX(デジタルトランスフォーメーション)の本質を知ることはビジネスパーソンにとって必須となりつつある。 自動車サブスクリプションやIT人材シェアなど多数の事業開発の経験を持つコンサルタント、岡村直人氏が解説する。 多彩なサービスを結びつける「広義のDX」と、社内の仕事を単にデジタル化する「狭義のDX」とは分けて考える必要がある 菅義偉首相は肝煎りの政策として「デジタル庁」の創設に向けた準備を進めています。 国家を挙げてDXを推進するという姿勢を示したもので、「脱ハンコ」などの方針を打ち出しています。 経営者への認知はいまひとつ いまや国が積極的な姿勢を見せるDXですが、一般の人々への認知度はどうでしょうか。 Googleトレンドで過去5年間の「デジタルトランスフォーメーション」の推移を表示。 確かに認知度は上がっていますが、まだまだ正しい理解は進んでいないようです。 日本国内企業の経営者・役員に実施した調査結果(有効回答数は574件)。 さらに「知っている」と答えた経営者の中でも「関心がある」という人はわずか34.3%という結果でした。
When Do We Trust AI’s Recommendations More Than People’s? A Practical Guide to Building Ethical AI. Companies are leveraging data and artificial intelligence to create scalable solutions — but they’re also scaling their reputational, regulatory, and legal risks.
For instance, Los Angeles is suing IBM for allegedly misappropriating data it collected with its ubiquitous weather app. Optum is being investigated by regulators for creating an algorithm that allegedly recommended that doctors and nurses pay more attention to white patients than to sicker black patients. Goldman Sachs is being investigated by regulators for using an AI algorithm that allegedly discriminated against women by granting larger credit limits to men than women on their Apple cards.
Facebook infamously granted Cambridge Analytica, a political firm, access to the personal data of more than 50 million users. Just a few years ago discussions of “data ethics” and “AI ethics” were reserved for nonprofit organizations and academics. What Not to Do First, there is the academic approach. AI ethics does not come in a box. AIを使ったシステム開発でおすすめの開発会社10社 【2020年版】|発注成功のための知識が身に付く【発注ラウンジ】 RPAツール比較27選 - 価格や機能. ボクシルおすすめのRPAツールを特徴や価格で比較して紹介!

種類が多くわかりづらいRPAツールの違いを詳しく解説します。 あなたの会社も、手作業で非効率だった業務から開放されてみませんか? RPAツールとは. The 2020 Gartner Magic Quadrant for Data Science and Machine-Learning Platforms. Getting Started witj Kaggle for Beginners. Overview Kaggle can often be intimating for beginners so here’s a guide to help you started with data science competitionsWe’ll use the House Prices prediction competition on Kaggle to walk you through how to solve Kaggle projects Kaggle your way to the top of the Data Science World!
Kaggle is the market leader when it comes to data science hackathons. I started my own data science journey by combing my learning on both Analytics Vidhya as well as Kaggle – a combination that helped me augment my theoretical knowledge with practical hands-on coding. Now, here’s the thing about Kaggle. In this article, I am going to ease that transition for you.
We will understand how to make your first submission on Kaggle by working through their House Price competition. You can also check out the DataHack platform which has some very interesting data science competitions as well. Please note that I’m assuming you’re familiar with Python and linear regression. Table of Contents Importing the Dataset in Kaggle. Learn tidymodels with my supervised machine learning course. Today I am happy to announce that a new tidymodels-centric version of my free, online, interactive course, Supervised Machine Learning: Case Studies in R, has been published!

🎉 This is at least the third version of this course I’ve built at this point 😁 but I believe it to be the best, in terms of how it communicates machine learning concepts and how useful to your real-world problems the demonstrated code will be. Huge thanks to my RStudio teammates such as Alison Hill and Max Kuhn for their feedback during the editing process! Similar to the last time I launched this course, it provides four case studies using data from the real world for you to practice your predictive modeling skills. Supervised machine learning in R One question we sometimes field from R users is about choosing to use tidymodels vs. caret.
The back-end code execution uses Binder. Try it out. The Art of Storytelling in Analytics and Data Science. 6 Open Source Data Science Projects to Try at Home! Overview Work on your data science skills using these open source projectsThese open-source data science projects cover a broad range of topics, from computer vision to web analytics Introduction Have you found learning at home difficult?
Most of us are in the same boat – there are too many things to juggle during these tumultuous times and learning has, contrary to our initial expectations, taken a back seat. So how can we get back on track? One key thing that has helped me immensely is picking an open-source data science project and running with it. And these projects aren’t your run-of-the-mill data science projects. So, pick a project that intrigues you and start working on it today!