
The Website Obesity Crisis. Let me give you a concrete example.
I recently heard from a competitor, let’s call them ACME Bookmarking Co., who are looking to leave the bookmarking game and sell their website. While ACME has much more traffic than I do, I learned they only have half the daily active users. This was reassuring, because the hard part of scaling a bookmarking site is dealing with people saving stuff. We both had the same number of employees. They have an intern working on the project part time, while I dither around and travel the world giving talks. We have similar revenue per active user.
But where the projects differ radically is cost. I pay just over a thousand dollars a month for hosting, using my own equipment. Microservices without the Servers. Tim Wagner, AWS Lambda General Manager At LinuxCon/ContainerCon 2015 I presented a demo-driven talk titled, “Microservices without the Servers”.
In it, I created an image processing microservice, deployed it to multiple regions, built a mobile app that used it as a backend, added an HTTPS-based API using Amazon API Gateway and a website, and then unit and load tested it, all without using any servers. This blog recreates the talk in detail, stepping you through all the pieces necessary for each of these steps and going deeper into the architecture. FlatBuffers: Main Page. FlatBuffers is an efficient cross platform serialization library for C++, with support for Java, C# and Go.
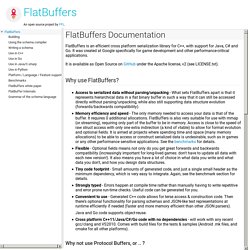
It was created at Google specifically for game development and other performance-critical applications. It is available as Open Source on GitHub under the Apache license, v2 (see LICENSE.txt). Why use FlatBuffers? Access to serialized data without parsing/unpacking - What sets FlatBuffers apart is that it represents hierarchical data in a flat binary buffer in such a way that it can still be accessed directly without parsing/unpacking, while also still supporting data structure evolution (forwards/backwards compatibility).Memory efficiency and speed - The only memory needed to access your data is that of the buffer. It requires 0 additional allocations. Why not use Protocol Buffers, or .. ? But all the cool kids use JSON! Read more about the "why" of FlatBuffers in the white paper. Improving Facebook's performance on Android with FlatBuffers. On Facebook, people can keep up with their family and friends through reading status updates and viewing photos.
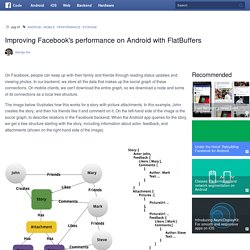
In our backend, we store all the data that makes up the social graph of these connections. On mobile clients, we can't download the entire graph, so we download a node and some of its connections as a local tree structure. The image below illustrates how this works for a story with picture attachments. In this example, John creates the story, and then his friends like it and comment on it. On the left-hand side of the image is the social graph, to describe relations in the Facebook backend. One of the key issues we address is how to represent and store the data in the app.
Parsing speed. We wanted to find a better storage format to increase the performance of our Android app. FlatBuffers In our exploration of alternate formats, we came across FlatBuffers, an open source project from Google. Class Person { String name; int friendshipStatus; Person spouse; List<Person>friends; } 5 Reasons to Use Protocol Buffers Instead of JSON For Your Next Service. Service-Oriented Architecture has a well-deserved reputation amongst Ruby and Rails developers as a solid approach to easing painful growth by extracting concerns from large applications.

These new, smaller services typically still use Rails or Sinatra, and use JSON to communicate over HTTP. Though JSON has many obvious advantages as a data interchange format - it is human readable, well understood, and typically performs well - it also has its issues. Where browsers and JavaScript are not consuming the data directly – particularly in the case of internal services – it’s my opinion that structured formats, such as Google’s Protocol Buffers, are a better choice than JSON for encoding data. If you’ve never seen Protocol Buffers before, you can check out some more information here, but don’t worry - I’ll give you a brief introduction to using them in Ruby before listing the reasons why you should consider choosing Protocol Buffers over JSON for your next service. Introducing Espresso - LinkedIn's hot new distributed document store.
Authors:Aditya Auradkar, Tom Quiggle Espresso is LinkedIn's online, distributed, fault-tolerant NoSQL database that currently powers approximately 30 LinkedIn applications including Member Profile, InMail (LinkedIn's member-to-member messaging system), portions of the Homepage and mobile applications, etc.

Espresso has a large production footprint at LinkedIn with over a dozen clusters in use. It hosts some of the most heavily accessed and valuable datasets at LinkedIn serving millions of records per second at peak. It is the source of truth for hundreds of terabytes (not counting replicas) of data. To meet the needs of online applications, LinkedIn traditionally used Relational Database Management Systems (RDBMSs) such as Oracle and key-value stores such as Voldemort - both serving different use cases.
Existing RDBMS solutions are painful for several reasons, including but not limited to: Espresso provides a hierarchical data model. Database A database is a container for tables. Table. Scalability.