
80legs - Custom Web Crawlers, Powerful Web Crawling, and Data Extraction. Webcrawler. Ein Webcrawler (auch Spider oder Searchbot) ist ein Computerprogramm, das automatisch das World Wide Web durchsucht und Webseiten analysiert.
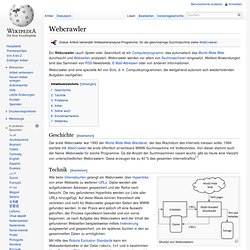
Webcrawler werden vor allem von Suchmaschinen eingesetzt. Weitere Anwendungen sind das Sammeln von RSS-Newsfeeds, E-Mail-Adressen oder von anderen Informationen. Webcrawler sind eine spezielle Art von Bots, d. h. Computerprogrammen, die weitgehend autonom sich wiederholenden Aufgaben nachgehen. Geschichte[Bearbeiten] Der erste Webcrawler war 1993 der World Wide Web Wanderer, der das Wachstum des Internets messen sollte. 1994 startete mit WebCrawler die erste öffentlich erreichbare WWW-Suchmaschine mit Volltextindex. Technik[Bearbeiten] Struktur von Webcrawlern Wie beim Internetsurfen gelangt ein Webcrawler über Hyperlinks von einer Webseite zu weiteren URLs. Probleme[Bearbeiten] Arten[Bearbeiten] Thematisch fokussierte Webcrawler werden als focused crawlers bzw. fokussierte Webcrawler bezeichnet. Scraper Site. Eine Scraper Site ist eine Webseite, die einen Großteil ihres Inhaltes von anderen Seiten kopiert hat.
Ziel ist es in der Regel, automatisiert und mit geringem Aufwand eine Seite zu erstellen, die in den Ergebnislisten der Suchmaschinen gut platziert ist. Die Scraper Site verdient durch eingeblendete Werbung (z. Category:World Wide Web. The World Wide Web (abbreviated as WWW or W3, commonly known as the web), is a system of interlinked hypertext documents accessed via the Internet.
With a web browser, one can view web pages that may contain text, images, videos, and other multimedia, and navigate between them via hyperlinks. The terms Internet and World Wide Web are often used in every-day speech without much distinction (as can be seen in the several subcategories below, titled "Internet ... " that should be "World Wide Web ... "). However, the Internet and the World Wide Web are not one and the same. The Internet is a global data communications system.
It is a hardware and software infrastructure that provides connectivity between computers. Subcategories This category has the following 35 subcategories, out of 35 total. Pages in category "World Wide Web" The following 200 pages are in this category, out of 200 total. Category:Web software. Category:Web crawlers. Web crawler. Not to be confused with offline reader.
For the search engine of the same name, see WebCrawler. Crawlers can validate hyperlinks and HTML code. They can also be used for web scraping (see also data-driven programming). Overview[edit] A Web crawler starts with a list of URLs to visit, called the seeds. The large volume implies that the crawler can only download a limited number of the Web pages within a given time, so it needs to prioritize its downloads. The number of possible URLs crawled being generated by server-side software has also made it difficult for web crawlers to avoid retrieving duplicate content.
Crawling policy[edit] PowerMapper. PowerMapper is a web crawler that automatically creates a site map of a website using thumbnails of each web page.
A number of map styles are available, although the cheaper Standard edition has fewer styles than the Professional edition. Map styles[edit] Site maps can be displayed in a number of different map styles which arrange sites into a tree structure. Some styles display thumbnails for each page, others use text-only presentation. Map styles include: Electrum - a simple thumbnail map styleElectrum 2.0 - a variation of the Electrum style that works better on larger sitesIsometric - a thumbnail map style using a pseudo-3D isometric projectionPage Cloud - a thumbnail map style with pages clustered into 3D cloudsSkyscrapers - an abstract representation of pages that looks like city blocksThumbtree - a hierarchical thumbnail map styleTable Map - a plain text list of pages in a tableTable of Contents - a plain text list of pagesTree View - an expanding table of contents.
Web scraping. Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.[1] Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
Web scraping a web page involves fetching it and extracting from it.[1][2] Fetching is the downloading of a page (which a browser does when you view the page). Therefore, web crawling is a main component of web scraping, to fetch pages for later processing. Once fetched, then extraction can take place. Scraper site. A scraper site is a website that copies all of its content from other websites using web scraping.
The purpose of creating such a site can be to collect advertising revenue or to manipulate search engine rankings by linking to other sites to improve their search engine ranking. In the last few years[when?] Scraper sites have proliferated at a high rate for spamming search engines. Open content is a common source of material for scraper sites. A search engine is not a scraper site itself; sites such as Yahoo and Google gather content from other websites and index it so that the index can be searched with keywords. Made for advertising[edit] Some scraper sites are created to make money by using advertising programs. Made for AdSense sites are considered sites that are spamming search engines and diluting the search results by providing surfers with less-than-satisfactory search results.
Legality[edit] Scraper sites may violate copyright law.
Data Mining. #2check#