
Physics Laboratory Tutorial : Error Analysis. Not all measurements are done with instruments whose error can be reliably estimated.

A classic example is the measuring of time intervals using a stopwatch. Of course, there will be a read-off error as discussed in the previous sections. Mission Base Creations. Feynman/CM-1 T-shirt photo shoot. Tamiko Thiel: The Connection Machine. [ NEW: the CM-1 t-shirt has been re-issued!

] The Connection Machine was the first commercial computer designed expressly to work on simulating intelligence and life. Richard Feynman and The Connection Machine. By W.
Daniel Hillis for Physics Today One day when I was having lunch with Richard Feynman, I mentioned to him that I was planning to start a company to build a parallel computer with a million processors. Richard Feynman and The Connection Machine. Parallel computing. The maximum possible speed-up of a single program as a result of parallelization is known as Amdahl's law.
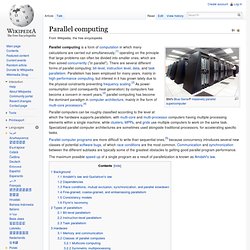
Background[edit] Traditionally, computer software has been written for serial computation. To solve a problem, an algorithm is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit on one computer. The Future is Hybrid – Trends in HPC. There is a large number of high performance processors available these days, each with its own characteristics, and the landscape is quickly changing with new processors being released.
There are CPUs, GPUs, FPGAs, Xeon Phi, DSPs – to name just a few. How should one decide which of these processors to use for a particular task? Or should even a combination of these processors be used jointly to get the best performance? And then, how to manage the complexity of handling these devices? In the following, we’ll attempt to answer these questions, in particular for users and applications in the financial services domain. Hardware Diversity The most common hardware processor is the CPU. In recent years, graphics processing units (GPUs) became popular for general purpose computing. Earlier this year, Intel released its Xeon Phi processor (see our blogpost).
Each of these platforms has its own characteristics as shown in the table below: High Performance Computing at the Oak Ridge National Laboratory. October 1, 2009 - 12:00pm - 1:00pm In the '70's, the "coin of the realm" in high-performance computing was to achieve Millions of FLoating Point Operations/Sec (MFLOPS) to solve scientific applications.
Papers by Olaf O. Storaasli. Author: Olaf O.

Storaasli (Oak Ridge National Laboratory, Future Technologies Group, Computer Science & Mathematics Division) Abstract High-Performance Computing (HPC) is undergoing revolutionary changes from its underlying hardware to the software used to solve applications. Nasa kth high performance supercomputer forum. Parallel computing. November 2012. Advanced reports that Oak Ridge National Laboratory was fielding the world’s fastest supercomputer were proven correct when the 40th edition of the twice-yearly TOP500 List of the world’s top supercomputers was released today (Nov. 12, 2012).
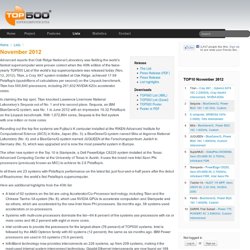
Titan, a Cray XK7 system installed at Oak Ridge, achieved 17.59 Petaflop/s (quadrillions of calculations per second) on the Linpack benchmark. Titan has 560,640 processors, including 261,632 NVIDIA K20x accelerator cores. In claiming the top spot, Titan knocked Lawrence Livermore National Laboratory’s Sequoia out of No. 1 and into second place. Sequoia, an IBM BlueGene/Q system, was No. 1 in June 2012 with an impressive 16.32 Petaflop/s on the Linpack benchmark. Introduction — PDC. University of Southampton - Southampton engineers a Raspberry Pi Supercomputer.
Olaf Storaasli. Olaf O.
Storaasli is a scientist at USEC Inc. He previously worked as a scientist at Oak Ridge National Laboratory (Computer Science and Mathematics Division's Future Technologies Group ) for seven years and at NASA for 35 years. He was PhD advisor for UT & GWU students, graduate instructor at GWU@NASA and CNU and mentored 25 NHGS students. Oak Ridge National Laboratory. Oak Ridge National Laboratory ( ORNL ) is a multiprogram science and technology national laboratory managed for the United States Department of Energy (DOE) by UT-Battelle .
ORNL is the largest science and energy national laboratory in the Department of Energy system by acreage. [ 1 ] ORNL is located in Oak Ridge , Tennessee , near Knoxville . ORNL's scientific programs focus on materials , neutron science, energy , high-performance computing , systems biology and national security . ORNL partners with the state of Tennessee , universities and industries to solve challenges in energy , advanced materials, manufacturing , security and physics .
Amdahl's law. The speedup of a program using multiple processors in parallel computing is limited by the sequential fraction of the program. For example, if 95% of the program can be parallelized, the theoretical maximum speedup using parallel computing would be 20× as shown in the diagram, no matter how many processors are used. Amdahl's law, also known as Amdahl's argument,[1] is used to find the maximum expected improvement to an overall system when only part of the system is improved.
It is often used in parallel computing to predict the theoretical maximum speedup using multiple processors. The law is named after computer architect Gene Amdahl, and was presented at the AFIPS Spring Joint Computer Conference in 1967. Speedup. In parallel computing, speedup refers to how much a parallel algorithm is faster than a corresponding sequential algorithm. Definition[edit] Speedup is defined by the following formula: where: p is the number of processors is the execution time of the sequential algorithm is the execution time of the parallel algorithm with p processors Linear speedup or ideal speedup is obtained when .
OpenMP. Table of Contents OpenMP is an Application Program Interface (API), jointly defined by a group of major computer hardware and software vendors. OpenMP provides a portable, scalable model for developers of shared memory parallel applications. The API supports C/C++ and Fortran on a wide variety of architectures. This tutorial covers most of the major features of OpenMP 3.1, including its various constructs and directives for specifying parallel regions, work sharing, synchronization and data environment. Runtime library functions and environment variables are also covered. Level/Prerequisites: This tutorial is one of the eight tutorials in the 4+ day "Using LLNL's Supercomputers" workshop. Message Passing Interface (MPI)
Table of Contents The Message Passing Interface Standard (MPI) is a message passing library standard based on the consensus of the MPI Forum, which has over 40 participating organizations, including vendors, researchers, software library developers, and users. The goal of the Message Passing Interface is to establish a portable, efficient, and flexible standard for message passing that will be widely used for writing message passing programs. As such, MPI is the first standardized, vendor independent, message passing library.
High Performance Computing: Training. Workshops | Workshop Schedule | Training Materials | Other Resources Workshops On-site Workshops—Throughout the year, Livermore Computing (LC) offers on-site workshops focusing on parallel programming, parallel tools, and the use of its High Performance Computing (HPC) systems. Introductory level workshops are intended for new users, with the goals of improving LC user productivity and minimizing the obstacles typically encountered by new users of such complex systems. Introductory level workshops typically include both lectures and hands-on exercises using the actual machines. Other workshops are targeted towards more experienced users and can cover a range of topics related to new technologies, performance/programming tools, ASC cross-platform training, and other topics as requested by LC users, researchers, and staff.
ASC Alliance Remote Workshops—ASC Alliances are invited to work with LC to deliver workshops at their respective sites. Suggestions? Workshop Schedule Training Materials. Introduction to Parallel Computing.