
Cassandra File System Design. The Cassandra File System (CFS) is an HDFS compatible filesystem built to replace the traditional Hadoop NameNode, Secondary NameNode and DataNode daemons.
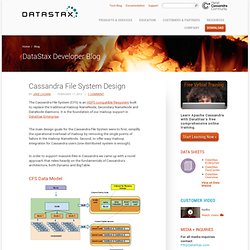
It is the foundation of our Hadoop support in DataStax Enterprise. The main design goals for the Cassandra File System were to first, simplify the operational overhead of Hadoop by removing the single points of failure in the Hadoop NameNode. Second, to offer easy Hadoop integration for Cassandra users (one distributed system is enough). Twitter/ambrose. Course: Hadoop Fundamentals I. MapReduce Patterns, Algorithms, and Use Cases « Highly Scalable. In this article I digested a number of MapReduce patterns and algorithms to give a systematic view of the different techniques that can be found on the web or scientific articles.
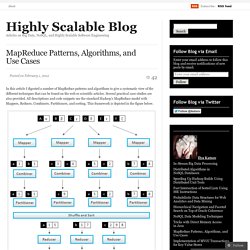
Several practical case studies are also provided. All descriptions and code snippets use the standard Hadoop’s MapReduce model with Mappers, Reduces, Combiners, Partitioners, and sorting. This framework is depicted in the figure below. Cloud9: A MapReduce Library for Hadoop. Cloud9 is a collection of Hadoop tools that tries to make working with big data a bit easier.
This software was designed with two goals in mind: First, to serve as a teaching tool for MapReduce and MapReduce algorithm design. Second, to provide a collection of useful tools on which to build other "big data" systems. Thinking At Scale. What is a “Hadoop”? Explaining Big Data to the C-Suite. Keep hearing about Big Data and Hadoop?
Having a hard time explaining what is behind the curtain? The term “big data” comes from computational sciences to describe scenarios where the volume of the data outstrips the tools to store it or process it. Bib. Atbrox. Attended Accel Partners Big Data conference last week.
It was a good event with many interesting people, a very crude estimate of distribution: 1/3 VCs/investors, 1/3 startup tech people, 1/3 big corp tech people +-. My personal 2 key takeaways from the conference: Realtime processing: hot topic with many companies creating their own custom solutions, but wouldn’t object having an exceptionally good opensource solution to gather around. Low-latency storage: emerging topic – or as quoted from the talk by Andy Becholsteim’s (Sun/Arista/Granite/Kealia/HighBAR co-founder and early Google-investor): “Hard Disk Drives are not keeping up.
Flash solving this problem just in time”. I think Andy Becholsteim’s table titled “Memory Hierarchi is Not Changing” sums up the low-latency storage discussion quite good. Mapreduce & Hadoop Algorithms in Academic Papers (3rd update) Hadoop Use Cases. Recent MapReduce Publications « Xtremweb’s Weblog. Processing big data. An Introduction to HDFS Federation. HDFS Federation HDFS Federation improves the existing HDFS architecture through a clear separation of namespace and storage, enabling generic block storage layer.
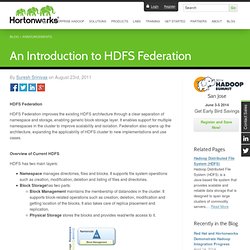
It enables support for multiple namespaces in the cluster to improve scalability and isolation. Federation also opens up the architecture, expanding the applicability of HDFS cluster to new implementations and use cases. Overview of Current HDFS. BRAD HEDLUND .com » Understanding Hadoop Clusters and the Network. This article is Part 1 in series that will take a closer look at the architecture and methods of a Hadoop cluster, and how it relates to the network and server infrastructure.

The content presented here is largely based on academic work and conversations I’ve had with customers running real production clusters. If you run production Hadoop clusters in your data center, I’m hoping you’ll provide your valuable insight in the comments below. Subsequent articles to this will cover the server and network architecture options in closer detail. Before we do that though, lets start by learning some of the basics about how a Hadoop cluster works. OK, let’s get started! The three major categories of machine roles in a Hadoop deployment are Client machines, Masters nodes, and Slave nodes.
Client machines have Hadoop installed with all the cluster settings, but are neither a Master or a Slave. In real production clusters there is no server virtualization, no hypervisor layer. Cheers, Brad. Realtime Hadoop usage at Facebook: The Complete Story. Next Generation of Apache Hadoop MapReduce – The Scheduler · Yahoo! Hadoop Blog. ## Introduction The previous post in this series covered the next generation of Apache Hadoop MapReduce in a broad sense, particularly its motivation, high-level architecture, goals, requirements, and aspects of its implementation.
In the second post in a series unpacking details of the implementation, we’d like to present the protocol for resource allocation and scheduling that drives application execution on a Next Generation Apache Hadoop MapReduce cluster. Hadoop 2.0 & OpenStack – PB&J ? « My missives. New developments are happening in the world Hadoop – even I had written a few blogs about it !

The latest blog from Arun has more insight and ideas on the scheduler and resource management … What caught my attention was the fact that two of my worlds suddenly converged – the world of Hadoop and the world of OpenStack … And they go well together … like the proverbial PB and Jelly … ! Videos & Webinars. Check out upcoming AWS events or events that AWS will be participating in: Webinar: Best Practices for AWS security, utilization, and cost optimization using CloudCheckr When: 3 April 2014, 11:00am PDT/2:00pm EDTSummary: Join this webinar to learn how to identify and address potential security misconfigurations and how to optimize AWS resource selection and utilization.
For example, you’ll see how customers are saving time and money by using CloudCheckr, an AWS technology partner, to automatically check for things like open permissions on Amazon S3 storage buckets, or misconfigured Auto Scaling groups.Register Now.