
Shira (shirabc) on Twitter. Apache Spark™ - Lightning-Fast Cluster Computing. Transcript of HBase for Architects Presentation - Nick Dimiduk. I was invited to speak at the Seattle Technical Forum’s first ”Big Data Deep Dive”.
The event was very well organized and all three presentations dove-tailed into each other quite well. No recording was made of the event, so this is a transcription of my talk based on notes and memory. The deck is available on slideshare, and embedded at the bottom of the post. Hi everyone, thanks for having me. My name is Nick Dimiduk, I’m an engineer on the HBase team at Hortonworks, contributing code and advising our customers on their HBase deployments. For this talk tonight, I want to provide an “architect’s overview” of HBase, meaning I’m going to make some claims about what HBase is and isn’t good at, and then defend those claims with details of HBase internals. I don’t usually include a users slide like this one and I won’t linger.
For a quick agenda, I want to briefly describe the context for HBase and then dive right into its implementation. The other Hadoop component is Hadoop MapReduce. Giraph - Welcome To Apache Giraph. Hama - a general BSP framework on top of Hadoop. The Hadoop ecosystem: the (welcome) elephant in the room (infographic) To say Hadoop has become really big business would be to understate the case.

At a broad level, it’s the focal point of a immense big data movement, but Hadoop itself is now a software and services market of its very own. In this graphic, we aim to map out the current ecosystem of Hadoop software and services — application and infrastructure software, as well as open source projects — and where those products fall in terms of use cases and delivery model. Click on a company name for more information about how they are using this technology. A couple of points about the methodology might be valuable: The first is that these are products and projects that are built with Hadoop in mind and that aim to either extend its utility in some way or expose its core functions in a new manner. This is the second installment of our four-part series on the past, present and future of Hadoop. How Hadoop Works? HDFS case study. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
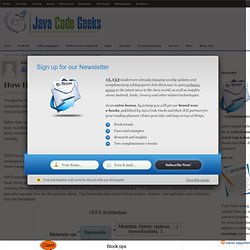
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. The Hadoop library contains two major components HDFS and MapReduce, in this post we will go inside each HDFS part and discover how it works internally. HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
HDFS exposes a file system namespace and allows user data to be stored in files. HDFS analysis I-DataNode.
Crunch. HBase. Using Apache HBase Effectively. Phoenix - SQL over HBase. Hive. Cloudera Impala: A Modern SQL Engine for Apache Hadoop. Innovations in Apache Hadoop MapReduce Pig Hive for Improving Query... OpenTSDB - A Distributed, Scalable Monitoring System. Optimizing Hive Queries. File Formats.
Distributed SQL Query Engine for Big Data.