
Web Scraping and Data Extraction Software. Screen Scraping, Web Scraping Software. Screen Scrape with Automation Anywhere: the leader in intelligent web scraping technology. Most businesses rely on the web or internal applications to gather data that is crucial to their decision making processes.
Automating information gathering whether they are from websites or applications can significantly help businesses reduce costs, time and manual errors. Automation Anywhere can help you easily automate screen scraping without any programming. Going beyond simple cutting and pasting information, Automation Anywhere intelligently scrapes information from a website or applications. Running on SMART Automation Technology®, it can automatically login to websites or applications, account for changes in the source website or applications, copy that information and transfer it to another application reliably in a format specified by you. Web Data Extraction, Data Extraction Software, Web Harvesting. Data Extraction, Web Screen Scraping Tool, Mozenda Scraper. Screen scraping & UI automation solutions for desktop and web.
Quand nous serons tous des dataminers. Djuggler advanced web scraper and data integration software. How to Scrape Websites for Data without Programming Skills. Searching for data to back up your story?
Just Google it, verify the accuracy of the source, and you’re done, right? Not quite. Accessing information to support our reporting is easier than ever, but very little information comes in a structured form that lends itself to easy analysis. You may be fortunate enough to receive a spreadsheet from your local public health agency. But more often, you’re faced with lists or tables that aren’t so easily manipulated. It’s not enough to copy those numbers into a story; what differentiates reporters from consumers is our ability to analyze data and spot trends. It often takes a lot of time and effort to produce programs that extract the information, so this is a specialty. Tutorial Outwit - récupération de listes. Après avoir décrit l’objet du logiciel Outwit Hub, passons à un petit tutorial qui vous permettra de l’expérimenter pour une application pratique: la récupération de listes de sites web.
Il vous faudra d’abord installer ou disposer de Firefox 3.x de Firefox. Ensuite, vous installerez la bêta d’Outwit Hub. Elle fonctionne sur Windows, MacOS comme sur Linux. Je vais utiliser ici un exemple de récupération de données structurées déjà exploité pour la préparation de mes supports de cours sur l’économie de l’innovation : la liste du Forbes 2000 qui regroupe les 2000 plus grandes entreprises mondiales.
Elle est porteuse d’une très grande richesse d’informations. Alors, lançons Firefox puis Outwit Hub à partir de l’icone installée dans la toolbar de Firefox par ce dernier comme indiqué ci-dessous. Dans la barre d’URL d’Outwit Hub, collez l’URL de Forbes. Cela affiche les données tabulées de la page HTML. Tutorial Outwit - récupération d'images. La récupération d’images avec Outwit fonctionne avec de nombreux sites et en particulier avec les moteurs de recherche.
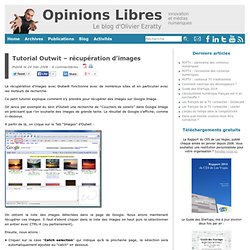
Ce petit tutoriel explique comment s’y prendre pour récupérer des images sur Google Image. On lance par exemple au sein d’Outwit une recherche de “Couchers de soleils” dans Google Image en précisant que l’on souhaite des images de grande taille. Le résultat de Google s’affiche, comme ci-dessous. A partir de là, on clique sur le Tab “Images” d’Outwit : On obtient la liste des images détectées dans la page de Google. Ensuite, nous allons : Cliquer sur la case “Catch selection” qui indique qu’à la prochaine page, la sélection sera automatiquement ajoutée au “catch” en dessous. Ce processus par étapes sera certainement simplifié dans les versions à venir d’Outwit. A ce stade, on peut lancer un diaporama des images récupérées, dont le nombre est indiqué en bas au dessus du “Catch”.
Et on vérifie qu’elles sont bien dans le répertoire de la sauvegarde. Et voilà le travail ! Moissonner le web avec Outwit. Le web, ses sites et les moteurs de recherche ont une particularité : ils présentent des tonnes d’information, mais en général, faiblement structurées.

La couche de présentation “web/HTML” détruit la structure originelle des informations, très souvent stockées dans des bases de données. Il en résulte des silos de données disparates difficiles à exploiter. Pourtant, des trésors d’informations sont disponibles qui pourraient être mieux exploitées : données financières, listes diverses, comparaisons de prix, listes d’objets à vendre, etc. Cela fait des années que les chercheurs et spécialistes des standards du web cherchent une réponse. Elle s’appelle le plus souvent “web sémantique”, voire “web services”. Les “services web” permettant quant à eux d’interroger les sites à partir de logiciels, comme si on interrogeait une base de données (pour faire simple), ne se sont pas plus généralisés.
Résultat, le web sémantique est pour l’instant dans les limbes. L’équipe Le produit Les utilisateurs. OutWit - Harvest The Web. OutWit Hub.