
Portail:Probabilités et statistiques. Statistics, Probability, and Survey Sampling. Probabilistic logic network. A probabilistic logic network (PLN) is a novel conceptual, mathematical and computational approach to uncertain inference; inspired by logic programming, but using probabilities in place of crisp (true/false) truth values, and fractional uncertainty in place of crisp known/unknown values.

In order to carry out effective reasoning in real-world circumstances, artificial intelligence software must robustly handle uncertainty. However, previous approaches to uncertain inference do not have the breadth of scope required to provide an integrated treatment of the disparate forms of cognitively critical uncertainty as they manifest themselves within the various forms of pragmatic inference. Going beyond prior probabilistic approaches to uncertain inference, PLN is able to encompass within uncertain logic such ideas as induction, abduction, analogy, fuzziness and speculation, and reasoning about time and causality.
Goal[edit] Implementation[edit] References[edit] Internet Glossary of Statistical Terms by Dr. Howard S. Hoffman. STATISTIQUES Excel facile simple. Online Statistics Calculator, basic math statistics, Tutorial. Indicateurs & Stats. Les pièges et erreurs statistiques. Une connaissance des statistiques est vitale pour notre compréhension du monde, mais une connaissance incomplète de celles-ci peut piéger celui qui n'est pas méfiant.

Les "pièges statistiques" pourraient être définis comme les "moyens" par lesquels les statistiques peuvent être mal interprétées. Une meilleure connaissance de ces pièges est importante parce que les statistiques jouent un rôle vital dans la prise de décision, qu'elle soit politique, scientifique, dans le monde des affaires ou lorsque vous devez prendre une décision (ou votre médecin) sur le traitement le plus adéquat à prendre quand vous êtes malade. Dans cet article nous donnerons plusieurs exemples d'interprétations erronées ou de mauvaises utilisations des statistiques.
Randomisation et double-aveugle Un des premiers aspects de l'erreur statistique, dans le cadre d'études scientifiques, est celui du respect de ces deux conditions que sont la randomisation et le double-aveugle. Le piège du contrôle unique. Interactive Statistical Calculation Pages. Game Mechanics & Design. Ulike.net : share everything you like.
Abaque de Régnier. Un article de Wikipédia, l'encyclopédie libre.
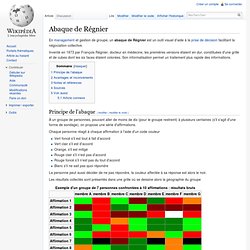
En management et gestion de groupe, un abaque de Régnier est un outil visuel d'aide à la prise de décision facilitant la négociation collective. Inventé en 1973 par François Régnier, docteur en médecine, les premières versions étaient en dur, constituées d'une grille et de cubes dont les six faces étaient colorées. Son informatisation permet un traitement plus rapide des informations. Principe de l'abaque[modifier | modifier le code] VOXCRACY - LE VOTE INTELLIGENT.
Louisa Mellor » Micro Mart ‘Gamification & the Web’ Micro Mart ‘Gamification & the Web’ How Gamification is Changing the Web Louisa Mellor Life would be a lot easier for web and software designers if human beings weren’t so complex.

Getting people to keep returning to your website or use your application would be child’s play if there was only a switch you could flip in people’s heads to make them do just that. Journal of Artificial Societies and Social Simulation. Modelling Research Policy: Ex-Ante Evaluation of Complex Policy Instruments Petra Ahrweiler, Michel Schilperoord, Andreas Pyka and Nigel Gilbert The Complexities of Agent-Based Modeling Output Analysis Ju-Sung Lee, Tatiana Filatova, Arika Ligmann-Zielinska, Behrooz Hassani-Mahmooei, Forrest Stonedahl, Iris Lorscheid, Alexey Voinov, Gary Polhill, Zhanli Sun and Dawn C.

Interpolation search. Interpolation search (sometimes referred to as extrapolation search) is an algorithm for searching for a given key value in an indexed array that has been ordered by the values of the key.

It parallels how humans search through a telephone book for a particular name, the key value by which the book's entries are ordered. In each search step it calculates where in the remaining search space the sought item might be, based on the key values at the bounds of the search space and the value of the sought key, usually via a linear interpolation. The key value actually found at this estimated position is then compared to the key value being sought. If it is not equal, then depending on the comparison, the remaining search space is reduced to the part before or after the estimated position. Inférer, qu'est-ce que cela veut dire ? A Reality Check on Big Data. A Reality Check on Big Data By Peter Sweeney (@petersweeney) The fervor around big data continues to grow.

The World Economic Forum and The New York Times are jumping on the bandwagon. Comparison of technical filter mechanisms and defense mechanisms of the human mind. Looking for new paradigms in artificial intelligence, we are investigating functionalities of the human thinking process to manipulate information and filter perceptions.

In this paper we introduce defense mechanisms of the human mind to be applied in artificial intelligence. We compare functionalities of defense mechanisms of the human mind with nowadays used filter mechanisms in artificial intelligence and explain reasons why defense mechanisms of the human mind open a broad new spectrum of possibilities and opportunities for artificial intelligence. In particular are these the defense mechanisms repression, deferral, sublimation, projection, disavowal, isolation, separation, depreciation and idealization.
Bayesian Links. Bayes and Bayes Theorem Bayesian Calculators Links to Experiments on Bayes Theorem Experiment on the Cab Problem.

Bayes' Theorem. An Intuitive Explanation of Bayes' Theorem Bayes' Theorem for the curious and bewildered; an excruciatingly gentle introduction.

Your friends and colleagues are talking about something called "Bayes' Theorem" or "Bayes' Rule", or something called Bayesian reasoning. They sound really enthusiastic about it, too, so you google and find a webpage about Bayes' Theorem and... Bayesian statistics theorem holds its own - but use with caution. (Phys.org) —In a Perspective in Science magazine this week, a Stanford Professor of Statistics re-examines Bayes' Theorem, its varying fortunes over the two-and-a-half centuries since it was proposed, and its current boom in popularity and likely future.
Bayes' Theorem was proposed by Thomas Bayes in the 18th century, and it combines newly acquired data with prior data to predict an outcome. In his paper, Professor Bradley Efron of Stanford University, presents the example of predicting whether twins are likely to be fraternal or identical in his overview of the theorem. In Professor Brad Efron's example, there are two categories of data to be considered: the newly acquired data (that sonograms show a pregnant woman is carrying twin boys), and the prior data (the fact that one-third of twins are identical). Identical twins are twice as likely to produce twin boy sonograms because identical twins are always the same sex while fraternal twins have only a 50:50 chance of being the same sex.
Bayesian Calculator. How to use the Calculator 1. To use this program for first time, work through the following example. Classification naïve bayésienne. Un article de Wikipédia, l'encyclopédie libre. Personnal Data. Présentation du projet "MesInfos. Le projet MesInfos vise à rassembler un noyau d’entreprises et d’administrations partenaires, dans le but d’explorer de manière concrète ce qui pourrait transformer la relation entre les individus et les organisations (entreprises et administrations) : le partage des données personnelles que détiennent les organisations avec les individus qu’elles concernent, pour qu’ils en fassent… ce qu’ils veulent.
Télécharger le dossier de présentation de MesInfos MesInfos : la piste de "l’outillage" des individus Depuis des décennies, les entreprises et les administrations se sont dotées de moyens sans cesse plus performants de capturer, retenir et exploiter les données relatives à leurs clients et usagers. Un véritable retournement de la relation client s’engage. List of data structures. Open Cog. Introducing Primal Assistants: A framework for software agents. Primal does a lot of heavy lifting in knowledge representation and content filtering. If you ask it to grab you some relevant content around your interests, it will do precisely that. But what if you don’t want to have to ask? Search engines are fantastic, but they still require that you go to them and then try to figure out how to formulate your query in a way that gets you decent results.
Twitter is closer to emulate a Neural Network than Facebook. When we think of Twitter and the innovation behind it, the first thing we all think is 140. 140 characters is without a doubt an amazing innovation that Twitter introduced which makes communication flow faster, forces twitters to summarize a piece of news or information, or an idea or an opinion and allows followers to get information or an idea faster as well. Also, after the introduction of url shorteners (tinyurl,com originally and many others later on such as bit.ly) an emergent property of Twitter came to life: the linked web. Any blog post or news article out there could be potentially linked multiple times in Twitter with quick summaries and opinions. Other emerging properties or elements in Twitter are:. Tags, early on twitters started using tags as a way to group events or themes together and follow them separately.. Wimmics is a joint research team between Inria Sophia Antipolis - Méditerranée and I3S (CNRS and Université Nice Sophia Antipolis).
Agent-based model. An agent-based model (ABM) is one of a class of computational models for simulating the actions and interactions of autonomous agents (both individual or collective entities such as organizations or groups) with a view to assessing their effects on the system as a whole. It combines elements of game theory, complex systems, emergence, computational sociology, multi-agent systems, and evolutionary programming. API. Data integration. Data integration involves combining data residing in different sources and providing users with a unified view of these data.[1] This process becomes significant in a variety of situations, which include both commercial (when two similar companies need to merge their databases) and scientific (combining research results from different bioinformatics repositories, for example) domains.
Data integration appears with increasing frequency as the volume and the need to share existing data explodes.[2] It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. In management circles, people frequently refer to data integration as "Enterprise Information Integration" (EII). History[edit] ISIF. Semi automated... Quantum Machine Learning Singularity from Google, Kurzweil and Dwave ? Computerized brain made of GPUs could be the future of artificial intelligence. Berkeley Video Course. Category:Data structures. In computer science, a data structure is a way of storing data in a computer so that it can be used efficiently. Data structure.